語法突顯最佳化
2017 年 2 月 8 日 - Alexandru Dima
Visual Studio Code 1.9 版本包含一項很棒的效能改進,我們一直在努力進行,我想告訴大家它的故事。
TL;DR (太長不看) TextMate 主題在 VS Code 1.9 中看起來會更像作者的本意,同時呈現速度更快,記憶體消耗更少。
語法突顯
語法突顯通常包含兩個階段。語法符號會被指派給原始碼,然後它們會成為主題的目標,被指派色彩,然後,您的原始碼就會以色彩呈現。它是將文字編輯器變成程式碼編輯器的功能。
VS Code (以及 Monaco Editor) 中的語法符號化是逐行執行的,從上到下,一次完成。語法符號化器可以在語法符號化行的末尾儲存一些狀態,這會在語法符號化下一行時傳回。這是許多語法符號化引擎使用的技術,包括 TextMate 文法,它允許編輯器在使用者進行編輯時僅重新語法符號化一小部分行。
大多數時候,在一行上輸入只會導致該行重新進行語法符號化,因為語法符號化器會傳回相同的結束狀態,並且編輯器可以假設後續行不會獲得新的語法符號
更少見的情況是,在一行上輸入會導致目前行和下方某些行 (直到遇到相同的結束狀態) 重新進行語法符號化/重新繪製
我們過去如何表示語法符號
VS Code 編輯器的程式碼在 VS Code 存在之前就已經編寫完成。它以 Monaco Editor 的形式在各種 Microsoft 專案中發布,包括 Internet Explorer 的 F12 工具。我們當時的一個要求是減少記憶體用量。
過去,我們是手動編寫語法符號化器 (即使在今天,在瀏覽器中解譯 TextMate 文法仍然是不可行的方式,但那是另一個故事)。對於以下行,我們會從手動編寫的語法符號化器中獲得以下語法符號
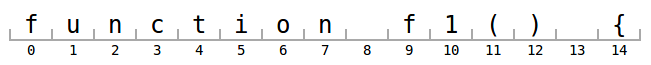
tokens = [
{ startIndex: 0, type: 'keyword.js' },
{ startIndex: 8, type: '' },
{ startIndex: 9, type: 'identifier.js' },
{ startIndex: 11, type: 'delimiter.paren.js' },
{ startIndex: 12, type: 'delimiter.paren.js' },
{ startIndex: 13, type: '' },
{ startIndex: 14, type: 'delimiter.curly.js' }
];
保留該語法符號陣列在 Chrome 中會佔用 648 位元組,因此儲存這樣的物件在記憶體方面相當昂貴 (每個物件執行個體都必須保留空間來指向其原型、其屬性清單等)。我們目前的機器確實有大量 RAM,但為 15 個字元的行儲存 648 位元組是無法接受的。
因此,當時我們想出了一種二進位格式來儲存語法符號,這種格式一直使用到 VS Code 1.8,包括在內。假設會有重複的語法符號類型,我們將它們收集在一個單獨的對應中 (每個檔案),執行類似以下的操作
// 0 1 2 3 4
map = ['', 'keyword.js', 'identifier.js', 'delimiter.paren.js', 'delimiter.curly.js'];
tokens = [
{ startIndex: 0, type: 1 },
{ startIndex: 8, type: 0 },
{ startIndex: 9, type: 2 },
{ startIndex: 11, type: 3 },
{ startIndex: 12, type: 3 },
{ startIndex: 13, type: 0 },
{ startIndex: 14, type: 4 }
];
然後我們會將 startIndex (32 位元) 和 type (16 位元) 編碼到 JavaScript 數字具有的 53 個尾數位元中的 48 位元中。我們的語法符號陣列最終會像這樣,而對應陣列將在整個檔案中重複使用
tokens = [
// type startIndex
4294967296, // 0000000000000001 00000000000000000000000000000000
8, // 0000000000000000 00000000000000000000000000001000
8589934601, // 0000000000000010 00000000000000000000000000001001
12884901899, // 0000000000000011 00000000000000000000000000001011
12884901900, // 0000000000000011 00000000000000000000000000001100
13, // 0000000000000000 00000000000000000000000000001101
17179869198 // 0000000000000100 00000000000000000000000000001110
];
保留這個語法符號陣列在 Chrome 中會佔用 104 位元組。元素本身應該只佔用 56 位元組 (7 個 64 位元數字),其餘部分可能可以用 v8 儲存陣列的其他中繼資料來解釋,或者可能是以 2 的冪分配後端儲存。但是,記憶體節省是顯而易見的,並且隨著每行語法符號的增加而變得更好。我們對這種方法感到滿意,並且從那時起就一直使用這種表示法。
注意:可能有更緊湊的方式來儲存語法符號,但以二進位可搜尋的線性格式儲存它們,在記憶體用量和存取效能方面為我們提供了最佳的權衡。
語法符號 <-> 主題比對
我們認為遵循瀏覽器最佳實務會是個好主意,例如將樣式設定留給 CSS,因此在呈現上述行時,我們會使用 map 解碼二進位語法符號,然後使用如下所示的語法符號類型來呈現它
<span class="token keyword js">function</span>
<span class="token"> </span>
<span class="token identifier js">f1</span>
<span class="token delimiter paren js">(</span>
<span class="token delimiter paren js">)</span>
<span class="token"> </span>
<span class="token delimiter curly js">{</span>
我們會用 CSS 編寫主題 (例如 Visual Studio 主題)
...
.monaco-editor.vs .token.delimiter { color: #000000; }
.monaco-editor.vs .token.keyword { color: #0000FF; }
.monaco-editor.vs .token.keyword.flow { color: #AF00DB; }
...
結果相當不錯,我們可以在某處翻轉類別名稱,並立即將新主題套用至編輯器。
TextMate 文法
在 VS Code 發布時,我們有大約 10 個手動編寫的語法符號化器,主要用於 Web 語言,這絕對不足以滿足一般用途的桌上型程式碼編輯器。TextMate 文法 登場,這是一種描述性的語法符號化規則指定形式,已被許多編輯器採用。但有一個問題,TextMate 文法的工作方式與我們手動編寫的語法符號化器不太一樣。
TextMate 文法透過使用 begin/end 狀態或 while 狀態,可以推送跨越多個語法符號的範圍。以下是 JavaScript TextMate 文法下的相同範例 (為簡潔起見,忽略空白)

VS Code 1.8 中的 TextMate 文法
如果我們要剖析範圍堆疊,每個語法符號基本上都會得到一個範圍名稱陣列,我們會從語法符號化器中獲得如下所示的內容
tokens = [
{ startIndex: 0, scopes: ['source.js', 'meta.function.js', 'storage.type.function.js'] },
{ startIndex: 8, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 9,
scopes: [
'source.js',
'meta.function.js',
'meta.definition.function.js',
'entity.name.function.js'
]
},
{
startIndex: 11,
scopes: [
'source.js',
'meta.function.js',
'meta.parameters.js',
'punctuation.definition.parameters.js'
]
},
{ startIndex: 13, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 14,
scopes: [
'source.js',
'meta.function.js',
'meta.block.js',
'punctuation.definition.block.js'
]
}
];
所有的語法符號類型都是字串,而我們的程式碼尚未準備好處理字串陣列,更不用說對語法符號的二進位編碼的影響。因此,我們著手將範圍陣列「近似」* 成單一字串,使用以下策略
- 忽略最不具體的範圍 (即
source.js);它很少增加任何價值。 - 將每個剩餘範圍以
"."分隔。 - 移除重複的唯一片段。
- 使用穩定排序函數對剩餘片段進行排序 (不一定是詞典排序)。
- 以
"."連接片段。
tokens = [
{ startIndex: 0, type: 'meta.function.js.storage.type' },
{ startIndex: 9, type: 'meta.function.js' },
{ startIndex: 9, type: 'meta.function.js.definition.entity.name' },
{ startIndex: 11, type: 'meta.function.js.definition.parameters.punctuation' },
{ startIndex: 13, type: 'meta.function.js' },
{ startIndex: 14, type: 'meta.function.js.definition.punctuation.block' }
];
*:我們當時的做法完全錯誤,「近似」對此而言是一個非常委婉的詞 :)。
這些語法符號隨後就會「融入」並遵循與手動編寫的語法符號化器相同的程式碼路徑 (取得二進位編碼),然後也會以相同的方式呈現
<span class="token meta function js storage type">function</span>
<span class="token meta function js"> </span>
<span class="token meta function js definition entity name">f1</span>
<span class="token meta function js definition parameters punctuation">()</span>
<span class="token meta function js"> </span>
<span class="token meta function js definition punctuation block">{</span>
TextMate 主題
TextMate 主題使用 範圍選取器,這些選取器會選取具有特定範圍的語法符號,並將主題資訊套用至它們,例如色彩、粗體等。
假設有一個具有以下範圍的語法符號
// C B A
scopes = ['source.js', 'meta.definition.function.js', 'entity.name.function.js'];
以下是一些簡單的選取器,它們會比對,並依其等級排序 (遞減)
| 選取器 | C | B | A |
|---|---|---|---|
| source | source.js | meta.definition.function.js | entity.name.function.js |
| source.js | source.js | meta.definition.function.js | entity.name.function.js |
| meta | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition.function | source.js | meta.definition.function.js | entity.name.function.js |
| entity | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name.function | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name.function.js | source.js | meta.definition.function.js | entity.name.function.js |
觀察:
entity勝過meta.definition.function,因為它比對的範圍更具體 (分別為 A 勝過 B)。
觀察:
entity.name勝過entity,因為它們都比對相同的範圍 (A),但entity.name比entity更具體。
父選取器
為了讓事情變得更複雜一點,TextMate 主題也支援父選取器。以下是一些同時使用簡單選取器和父選取器的範例 (再次依其等級排序 (遞減))
| 選取器 | C | B | A |
|---|---|---|---|
| meta | source.js | meta.definition.function.js | entity.name.function.js |
| source meta | source.js | meta.definition.function.js | entity.name.function.js |
| source.js meta | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| source meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| entity | source.js | meta.definition.function.js | entity.name.function.js |
| source entity | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition entity | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name | source.js | meta.definition.function.js | entity.name.function.js |
| source entity.name | source.js | meta.definition.function.js | entity.name.function.js |
觀察:
source entity勝過entity,因為它們都比對相同的範圍 (A),但source entity也比對父範圍 (C)。
觀察:
entity.name勝過source entity,因為它們都比對相同的範圍 (A),但entity.name比entity更具體。
注意:還有第三種選取器,其中一種涉及排除範圍,我們在此不討論。我們沒有新增對這種類型的支援,而且我們注意到它在實際應用中很少使用。
VS Code 1.8 中的 TextMate 主題
以下是兩個 Monokai 主題規則 (此處以 JSON 呈現以求簡潔;原始規則為 XML)
...
// Function name
{ "scope": "entity.name.function", "fontStyle": "", "foreground":"#A6E22E" }
...
// Class name
{ "scope": "entity.name.class", "fontStyle": "underline", "foreground":"#A6E22E" }
...
在 VS Code 1.8 中,為了比對我們「近似」的範圍,我們會產生以下動態 CSS 規則
...
/* Function name */
.entity.name.function { color: #A6E22E; }
...
/* Class name */
.entity.name.class { color: #A6E22E; text-decoration: underline; }
...
然後我們會讓 CSS 將「近似」的範圍與「近似」的規則進行比對。但 CSS 比對規則與 TextMate 選取器比對規則不同,尤其是在等級方面。CSS 等級是根據比對的類別名稱數量而定,而 TextMate 選取器等級對於範圍具體性有明確的規則。
這就是為什麼 VS Code 中的 TextMate 主題看起來還可以,但始終不如作者的本意。有時,差異很小,但有時這些差異會完全改變主題的感覺。
天時地利人和
隨著時間的推移,我們已逐步淘汰手動編寫的語法符號化器 (最後一個,用於 HTML,僅在幾個月前)。因此,在今天的 VS Code 中,所有檔案都使用 TextMate 文法進行語法符號化。對於 Monaco Editor,我們已遷移到使用 Monarch (一種描述性的語法符號化引擎,其核心與 TextMate 文法相似,但更具表現力,並且可以在瀏覽器中執行) 來處理大多數支援的語言,並且我們已為手動語法符號化器新增了封裝函式。總之,這表示支援新的語法符號化格式將需要變更 3 個語法符號提供者 (TextMate、Monarch 和手動封裝函式),而且不會超過 10 個。
幾個月前,我們審查了 VS Code 核心中所有讀取語法符號類型的程式碼,並且我們注意到這些消費者只關心字串、正則運算式或註解。例如,括號比對邏輯會忽略包含範圍 "string"、"comment" 或 "regex" 的語法符號。
最近,我們已獲得內部合作夥伴 (Microsoft 內部使用 Monaco Editor 的其他團隊) 的許可,他們不再需要在 Monaco Editor 中支援 IE9 和 IE10。
可能最重要的是,編輯器最受歡迎的功能是 迷你地圖支援。為了在合理的時間內呈現迷你地圖,我們無法使用 DOM 節點和 CSS 比對。我們可能會使用畫布,而且我們需要知道 JavaScript 中每個語法符號的色彩,這樣我們才能用正確的色彩繪製這些小字母。
也許我們最大的突破是,我們不需要儲存語法符號,也不需要儲存它們的範圍,因為語法符號只會在主題比對它們或括號比對跳過字串方面產生效果。
最後,VS Code 1.9 的新功能
表示 TextMate 主題
以下是一個非常簡單的主題範例
theme = [
{ "foreground": "#F8F8F2" },
{ "scope": "var", "foreground": "#F8F8F2" },
{ "scope": "var.identifier", "foreground": "#00FF00", "fontStyle": "bold" },
{ "scope": "meta var.identifier", "foreground": "#0000FF" },
{ "scope": "constant", "foreground": "#100000", "fontStyle": "italic" },
{ "scope": "constant.numeric", "foreground": "#200000" },
{ "scope": "constant.numeric.hex", "fontStyle": "bold" },
{ "scope": "constant.numeric.oct", "fontStyle": "underline" },
{ "scope": "constant.numeric.dec", "foreground": "#300000" },
];
載入時,我們會為主題中出現的每個唯一色彩產生一個 ID,並將其儲存在色彩對應中 (與我們對上述語法符號類型所做的方式類似)
// 1 2 3 4 5 6
colorMap = ["reserved", "#F8F8F2", "#00FF00", "#0000FF", "#100000", "#200000", "#300000"]
theme = [
{ "foreground": 1 },
{ "scope": "var", "foreground": 1, },
{ "scope": "var.identifier", "foreground": 2, "fontStyle": "bold" },
{ "scope": "meta var.identifier", "foreground": 3 },
{ "scope": "constant", "foreground": 4, "fontStyle": "italic" },
{ "scope": "constant.numeric", "foreground": 5 },
{ "scope": "constant.numeric.hex", "fontStyle": "bold" },
{ "scope": "constant.numeric.oct", "fontStyle": "underline" },
{ "scope": "constant.numeric.dec", "foreground": 6 },
];
然後我們會從主題規則中產生一個 Trie 資料結構,其中每個節點都保存已解析的主題選項
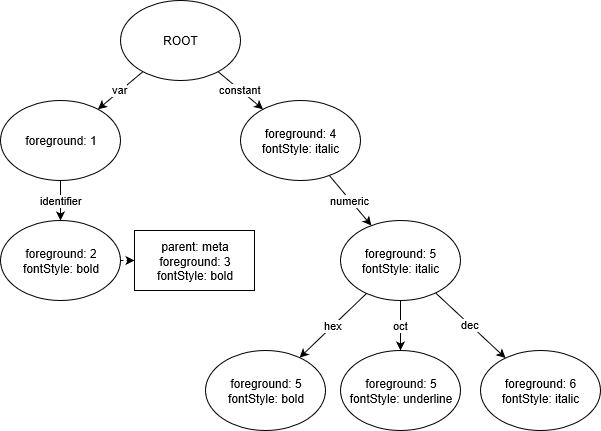
觀察:
constant.numeric.hex和constant.numeric.oct的節點包含將前景變更為5的指示,因為它們從constant.numeric繼承此指示。
觀察:
var.identifier的節點保存額外的父規則meta var.identifier,並會據此回答查詢。
當我們想知道如何為範圍設定主題時,我們可以查詢這個 trie。
例如
| 查詢 | 結果 |
|---|---|
| constant | 設定前景為 4,字型樣式為 斜體 |
| constant.numeric | 設定前景為 5,字型樣式為 斜體 |
| constant.numeric.hex | 設定前景為 5,字型樣式為 粗體 |
| var | 設定前景為 1 |
| var.baz | 設定前景為 1 (比對 var) |
| baz | 不執行任何動作 (未比對) |
| var.identifier | 如果存在父範圍 meta,則設定前景為 3,字型樣式為 粗體, 否則,設定前景為 2,字型樣式為 粗體 |
語法符號化的變更
VS Code 中使用的所有 TextMate 語法符號化程式碼都位於一個獨立的專案中,vscode-textmate,它可以獨立於 VS Code 使用。我們已變更在 vscode-textmate 中表示範圍堆疊的方式,使其成為 不可變的連結串列,它也儲存完全解析的 metadata。
當將新範圍推入範圍堆疊時,我們會在主題 trie 中查詢新範圍。然後我們可以立即計算範圍清單的完全解析的所需前景或字型樣式,根據我們從範圍堆疊繼承的內容以及主題 trie 傳回的內容。
一些範例
| 範圍堆疊 | 中繼資料 |
|---|---|
| ["source.js"] | 前景為 1,字型樣式為一般 (沒有範圍選取器的預設規則) |
| ["source.js","constant"] | 前景為 4,字型樣式為 斜體 |
| ["source.js","constant","baz"] | 前景為 4,字型樣式為 斜體 |
| ["source.js","var.identifier"] | 前景為 2,字型樣式為 粗體 |
| ["source.js","meta","var.identifier"] | 前景為 3,字型樣式為 粗體 |
當從範圍堆疊中彈出時,無需計算任何內容,因為我們可以只使用與先前範圍清單元素一起儲存的中繼資料。
以下是表示範圍清單中元素的 TypeScript 類別
export class ScopeListElement {
public readonly parent: ScopeListElement;
public readonly scope: string;
public readonly metadata: number;
...
}
我們儲存 32 位元的中繼資料
/**
* - -------------------------------------------
* 3322 2222 2222 1111 1111 1100 0000 0000
* 1098 7654 3210 9876 5432 1098 7654 3210
* - -------------------------------------------
* xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
* bbbb bbbb bfff ffff ffFF FTTT LLLL LLLL
* - -------------------------------------------
* - L = LanguageId (8 bits)
* - T = StandardTokenType (3 bits)
* - F = FontStyle (3 bits)
* - f = foreground color (9 bits)
* - b = background color (9 bits)
*/
最後,不再從語法符號化引擎發出語法符號作為物件
// These are generated using the Monokai theme.
tokens_before = [
{ startIndex: 0, scopes: ['source.js', 'meta.function.js', 'storage.type.function.js'] },
{ startIndex: 8, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 9,
scopes: [
'source.js',
'meta.function.js',
'meta.definition.function.js',
'entity.name.function.js'
]
},
{
startIndex: 11,
scopes: [
'source.js',
'meta.function.js',
'meta.parameters.js',
'punctuation.definition.parameters.js'
]
},
{ startIndex: 13, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 14,
scopes: [
'source.js',
'meta.function.js',
'meta.block.js',
'punctuation.definition.block.js'
]
}
];
// Every even index is the token start index, every odd index is the token metadata.
// We get fewer tokens because tokens with the same metadata get collapsed
tokens_now = [
// bbbbbbbbb fffffffff FFF TTT LLLLLLLL
0,
16926743, // 000000010 000001001 001 000 00010111
8,
16793623, // 000000010 000000001 000 000 00010111
9,
16859159, // 000000010 000000101 000 000 00010111
11,
16793623 // 000000010 000000001 000 000 00010111
];
並使用以下方式呈現
<span class="mtk9 mtki">function</span>
<span class="mtk1"> </span>
<span class="mtk5">f1</span>
<span class="mtk1">() {</span>
語法符號會以 Uint32Array 的形式直接從語法符號化器傳回。我們保留後端的 ArrayBuffer,對於上面的範例,它在 Chrome 中佔用 96 位元組。元素本身應該只佔用 32 位元組 (8 個 32 位元數字),但同樣地,我們可能觀察到一些 v8 中繼資料額外負荷。
一些數字
為了獲得以下測量結果,我選擇了三個具有不同特性和不同文法的檔案
| 檔案名稱 | 檔案大小 | 行數 | 語言 | 觀察 |
|---|---|---|---|---|
| checker.ts | 1.18 MB | 22,253 | TypeScript | TypeScript 編譯器中使用的實際原始碼檔案 |
| bootstrap.min.css | 118.36 KB | 12 | CSS | 最小化的 CSS 檔案 |
| sqlite3.c | 6.73 MB | 200,904 | C | C |
SQLite 的串連發行檔案
我已在 Windows 上功能強大的桌上型電腦 (使用 32 位元 Electron) 上執行測試。
我必須對原始碼進行一些變更,才能進行公平的比較,例如確保在兩個 VS Code 版本中使用完全相同的文法、關閉兩個版本中的豐富語言功能,或解除 VS Code 1.8 中不再存在於 VS Code 1.9 中的 100 個堆疊深度限制等。我也必須將 bootstrap.min.css 分割成多行,才能使每行低於 2 萬個字元。
語法符號化時間
| 檔案名稱 | 檔案大小 | 語法符號化在 UI 執行緒上以產生方式執行,因此我必須新增一些程式碼以強制其同步執行,才能測量以下時間 (呈現 10 次執行的中位數) | VS Code 1.8 | VS Code 1.9 |
|---|---|---|---|---|
| checker.ts | 1.18 MB | 加速 | 4606.80 毫秒 | 14.50% |
| bootstrap.min.css | 118.36 KB | 3939.00 毫秒 | 776.76 毫秒 | 46.41% |
| sqlite3.c | 6.73 MB | 416.28 毫秒 | 16010.42 毫秒 | 31.52% |
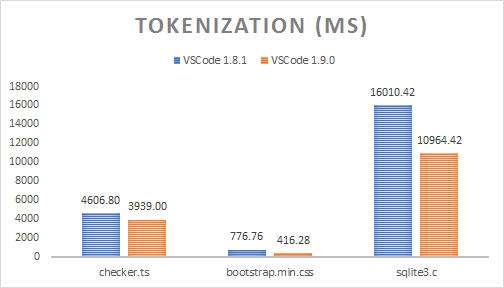
10964.42 毫秒
雖然語法符號化現在也執行主題比對,但時間節省可歸因於對每行執行單次傳遞。而以前,會有一個語法符號化傳遞,一個二次傳遞將範圍「近似」為字串,以及一個三次傳遞來二進位編碼語法符號,現在語法符號直接以二進位編碼方式從 TextMate 語法符號化引擎產生。需要進行垃圾回收的產生物件數量也大幅減少。
記憶體用量
| 檔案名稱 | 檔案大小 | 語法符號化在 UI 執行緒上以產生方式執行,因此我必須新增一些程式碼以強制其同步執行,才能測量以下時間 (呈現 10 次執行的中位數) | VS Code 1.8 | 摺疊功能佔用大量記憶體,尤其是對於大型檔案 (這是稍後再進行的優化),因此我已在關閉摺疊功能的情況下收集了以下堆積快照數字。這顯示模型所佔用的記憶體,不包括原始檔案字串 |
|---|---|---|---|---|
| checker.ts | 1.18 MB | 記憶體節省 | 3.37 MB | 22.60% |
| bootstrap.min.css | 118.36 KB | 2.61 MB | 267.00 KB | 24.60% |
| sqlite3.c | 6.73 MB | 201.33 KB | 27.49 MB | 22.83% |
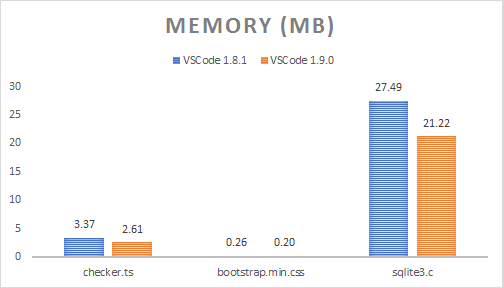
21.22 MB
記憶體用量減少可歸因於不再保留語法符號對應、具有相同中繼資料的連續語法符號的摺疊,以及使用 ArrayBuffer 作為後端儲存。我們可以透過始終將僅包含空格的語法符號摺疊到前一個語法符號中來進一步改進此處,因為空格的呈現色彩並不重要 (空格是不可見的)。
新的 TextMate 範圍檢查器小工具
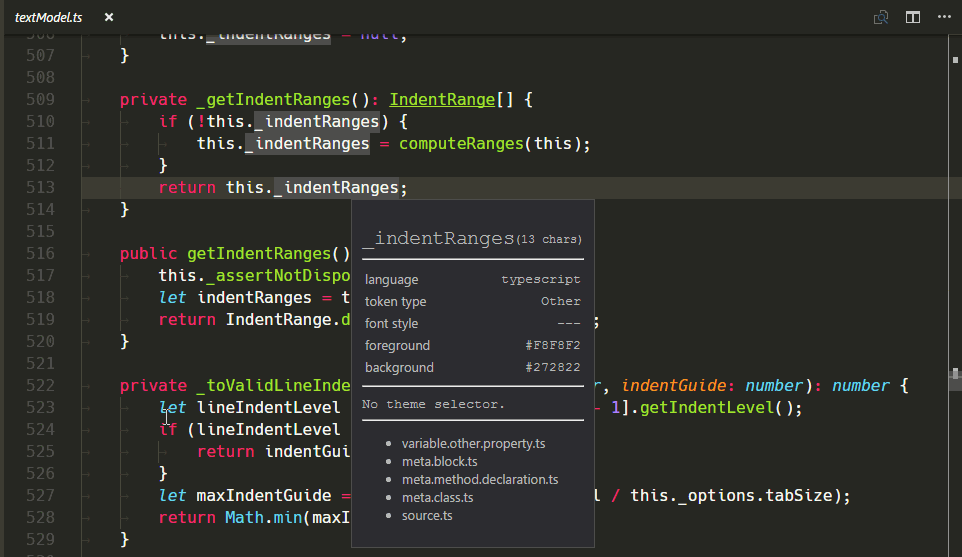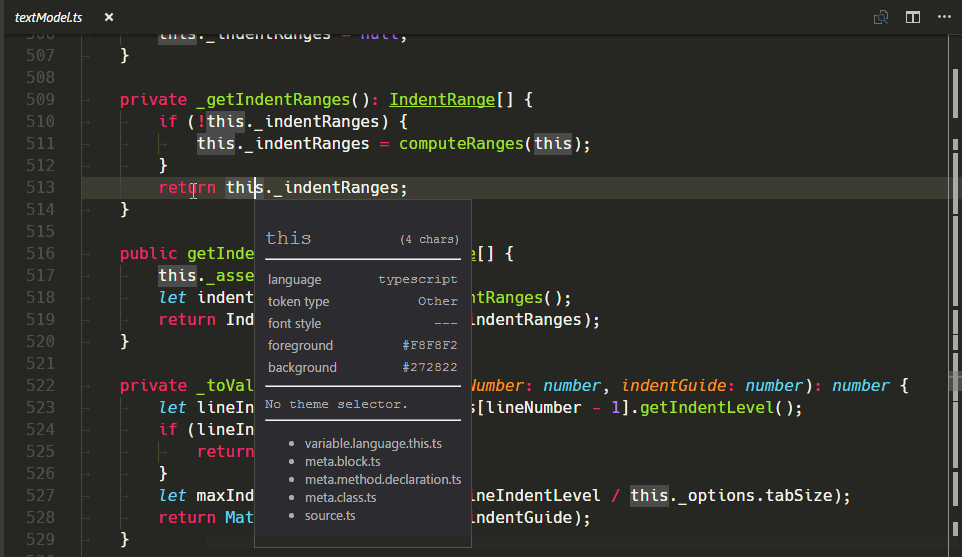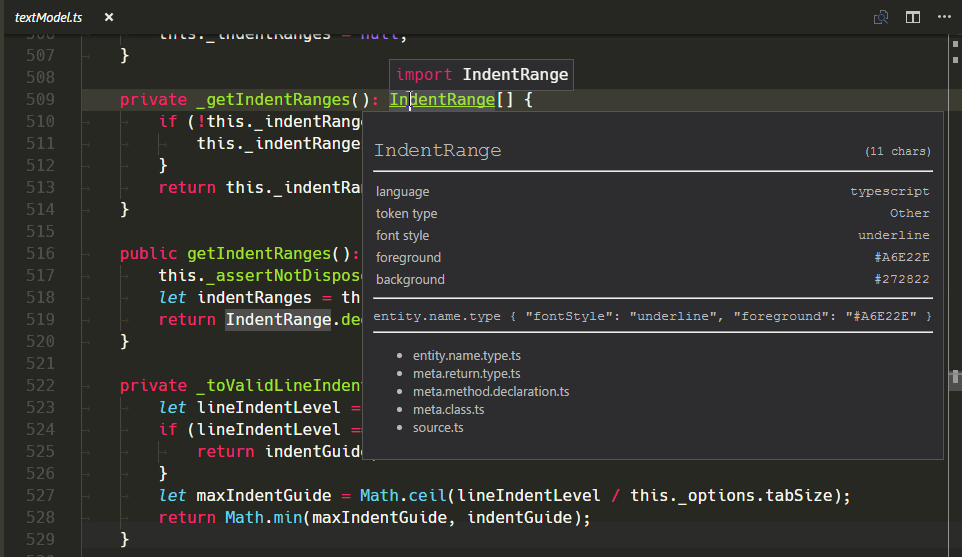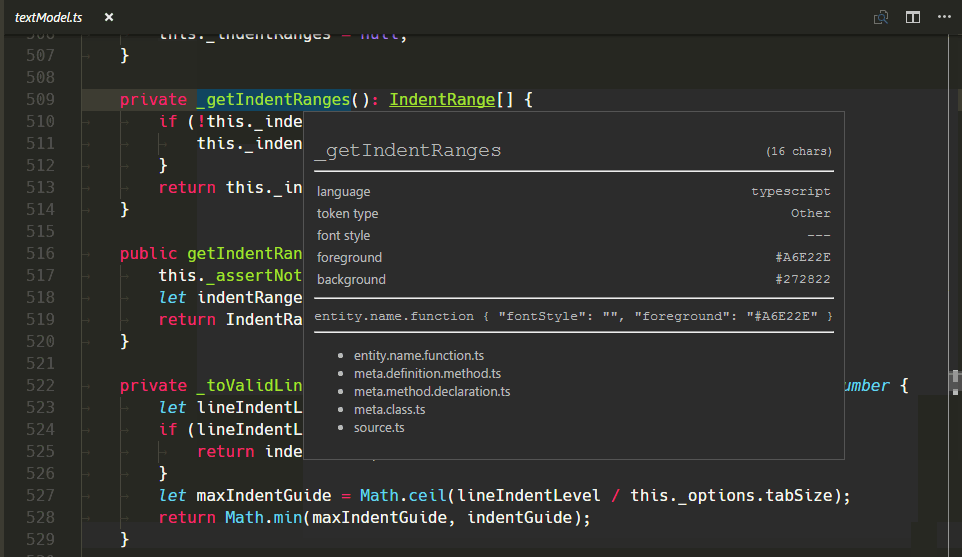
我們新增了一個新的小工具,以協助撰寫和偵錯主題或文法:您可以使用命令面板中的開發人員:檢查編輯器語法符號和範圍來執行它 (⇧⌘P (Windows、Linux Ctrl+Shift+P))。
驗證變更
在此編輯器元件中進行變更會帶來一些嚴重的風險,因為我們方法中的任何錯誤 (在新 trie 建立程式碼、新的二進位編碼格式等中) 都可能導致使用者可見的巨大差異。
在 VS Code 中,我們有一個整合套件,用於斷言我們在五個主題中撰寫的所有程式設計語言的色彩 (Light、Light+、Dark、Dark+、High Contrast)。當變更我們的其中一個主題以及更新特定文法時,這些測試都非常有幫助。73 個整合測試中的每一個都包含一個 fixture 檔案 (例如 test.c) 以及五個主題的預期色彩 (test_c.json),它們會在我們的 CI 建置上的每次提交時執行。
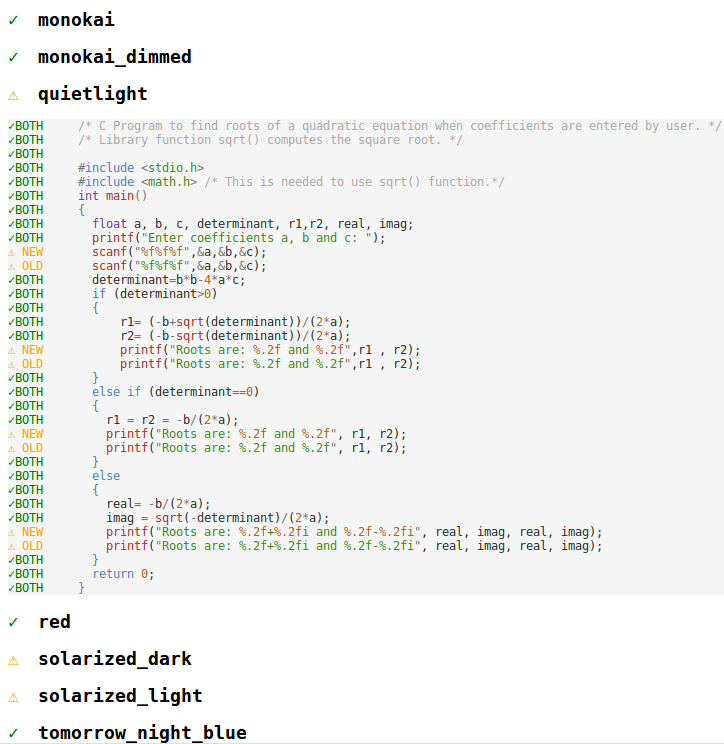
為了驗證語法符號化變更,我們已從這些測試中收集色彩化結果,跨越我們隨附的所有 14 個主題 (而不僅僅是我們撰寫的五個主題),使用舊的基於 CSS 的方法。然後,在每次變更之後,我們使用新的 trie 型邏輯執行相同的測試,並使用自訂建置的視覺差異 (和修補程式) 工具,我們會研究每個色彩差異,並找出色彩變更的根本原因。我們使用這種技術至少發現了 2 個錯誤,並且我們能夠變更我們的五個主題,以在 VS Code 版本之間獲得最小的色彩變更
變更前後
以下是各種色彩主題在 VS Code 1.8 和現在 VS Code 1.9 中的外觀
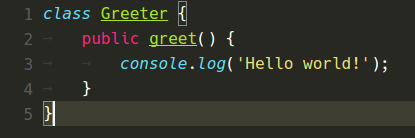
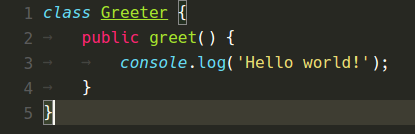
Monokai 主題


Quiet Light 主題
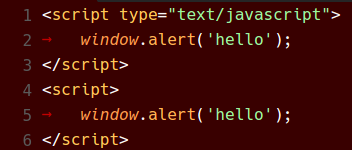
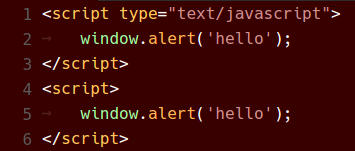
總結
Red 主題
我希望您會喜歡從升級到 VS Code 1.9 獲得的額外 CPU 時間和 RAM,並且我們可以繼續協助您以高效且愉快的方式編碼。
Coding 愉快!