括號配對著色速度提升 10,000 倍
2021 年 9 月 29 日,作者:Henning Dieterichs,@hediet_dev
在 Visual Studio Code 中處理深度巢狀括號時,可能難以判斷哪些括號互相配對,以及哪些沒有配對。
為了讓這件事變得更簡單,在 2016 年,一位名為 CoenraadS 的使用者開發了絕佳的 Bracket Pair Colorizer 擴充功能,以針對配對括號進行著色,並將其發佈到 VS Code Marketplace。此擴充功能變得非常受歡迎,現在是 Marketplace 上下載次數排名前 10 的擴充功能之一,安裝次數超過 600 萬次。
為了處理效能和準確性問題,在 2018 年,CoenraadS 接著推出了 Bracket Pair Colorizer 2,現在也擁有超過 300 萬次的安裝次數。
Bracket Pair Colorizer 擴充功能是 VS Code 擴充性的絕佳範例,並大量使用 Decoration API 來著色括號。

我們很高興看到 VS Code Marketplace 提供更多這類社群提供的擴充功能,所有這些功能都有助於以非常有創意的方式識別配對括號,包括:Rainbow Brackets、Subtle Match Brackets、Bracket Highlighter、Blockman 和 Bracket Lens。這些種類繁多的擴充功能顯示 VS Code 使用者確實渴望獲得對括號的更佳支援。
效能問題
不幸的是,Decoration API 的非增量特性,以及缺少對 VS Code 的 Token 資訊的存取權限,導致 Bracket Pair Colorizer 擴充功能在大型檔案上速度緩慢:當在 TypeScript 專案的 checker.ts 檔案 (程式碼超過 42k 行) 的開頭插入單一個括號時,大約需要 10 秒的時間,所有括號配對的色彩才會更新。在這 10 秒的處理期間,擴充功能主機程序會以 100% CPU 執行,而且所有由擴充功能 (例如自動完成或診斷) 驅動的功能都會停止運作。幸好,VS Code 的架構 確保 UI 保持回應,而且文件仍然可以儲存到磁碟。
CoenraadS 意識到此效能問題,並在擴充功能的第 2 版中投入大量心力來提高速度和準確性,方法是重複使用 VS Code 中的 Token 和括號剖析引擎。但是,VS Code 的 API 和擴充功能架構並非設計成允許在涉及數十萬個括號配對時,進行高效能的括號配對著色。因此,即使在 Bracket Pair Colorizer 2 中,在檔案開頭插入 { 之後,也需要一些時間,色彩才會反映新的巢狀層級
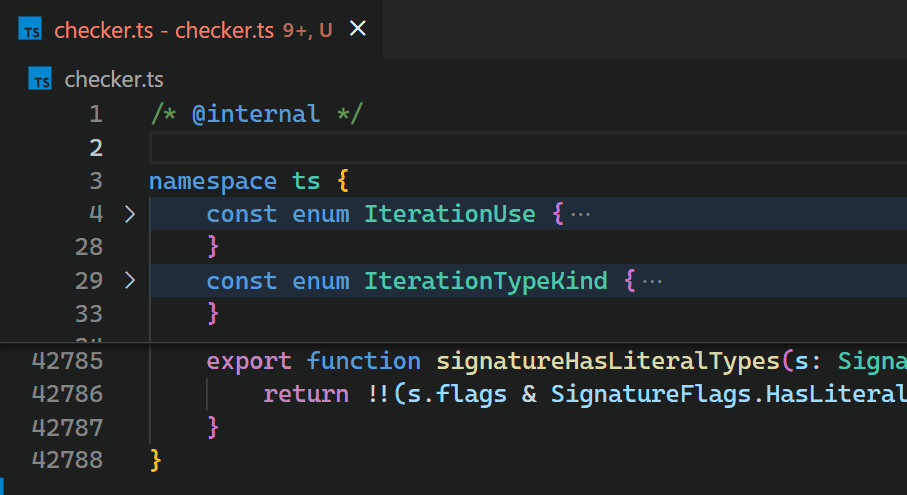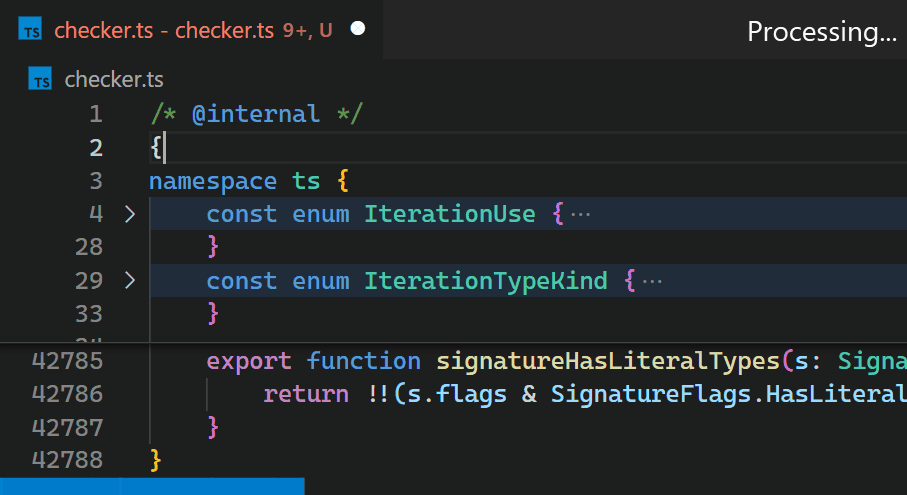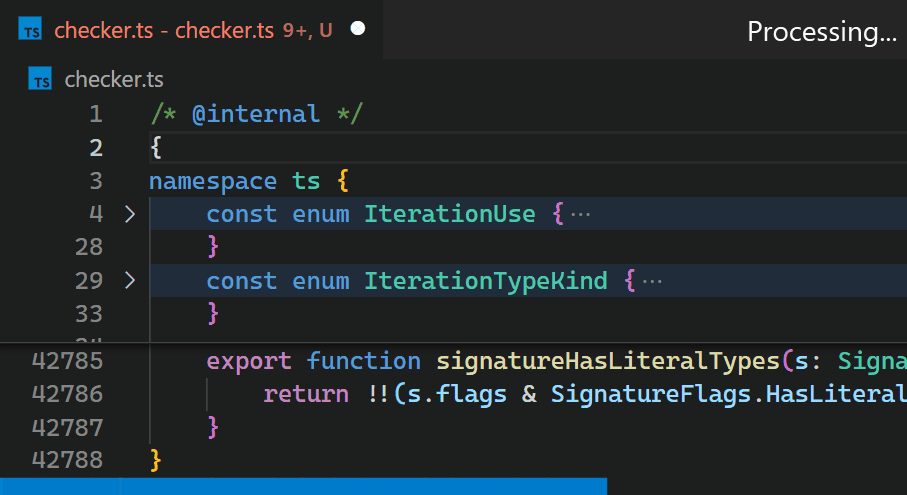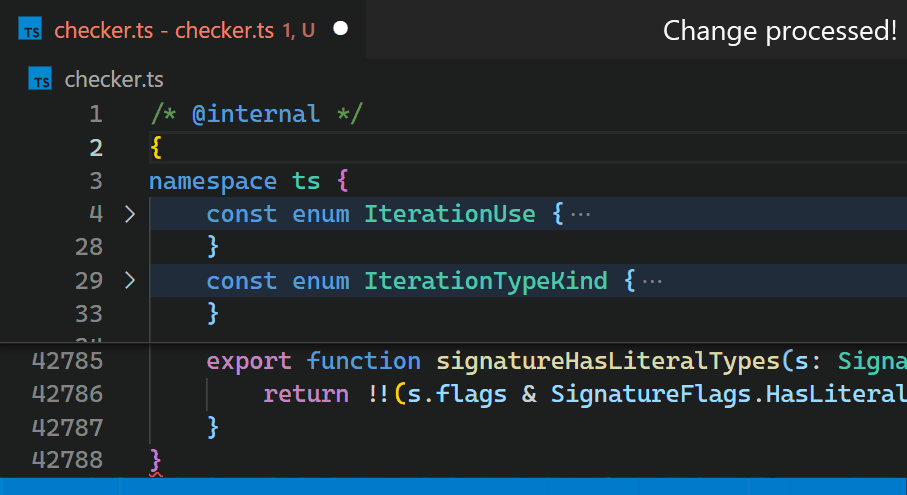
雖然我們很樂意直接改善擴充功能的效能 (這當然需要引入更多針對高效能案例最佳化的進階 API),但轉譯器和擴充功能主機之間的非同步通訊嚴重限制了實作為擴充功能時,括號配對著色的速度。此限制無法克服。尤其是,不應在括號配對出現在檢視區時立即非同步要求其色彩,因為這會在捲動大型檔案時造成明顯的閃爍。可以在 issue #128465 中找到相關討論。
我們的做法
相反地,在 1.60 更新中,我們在 VS Code 的核心中重新實作了擴充功能,並將此時間縮短到不到一毫秒 - 在此特定範例中,速度快了 10,000 倍以上。
此功能可以透過新增設定 "editor.bracketPairColorization.enabled": true 來啟用。
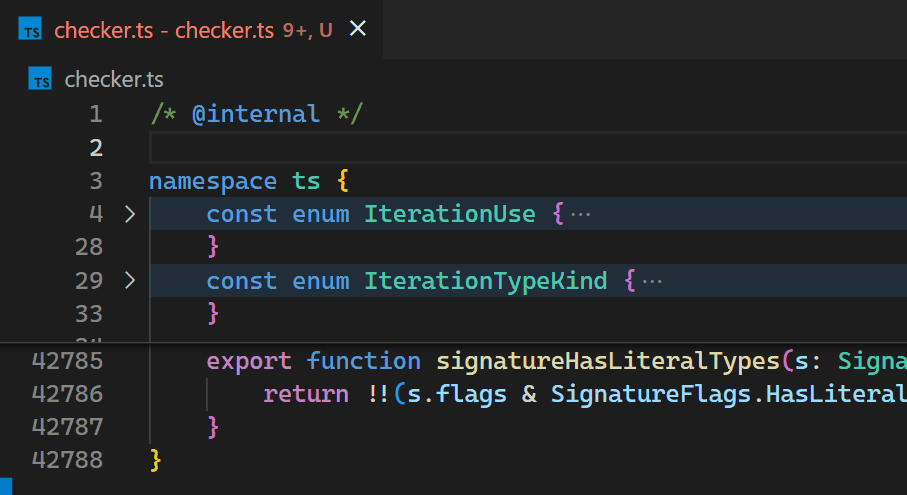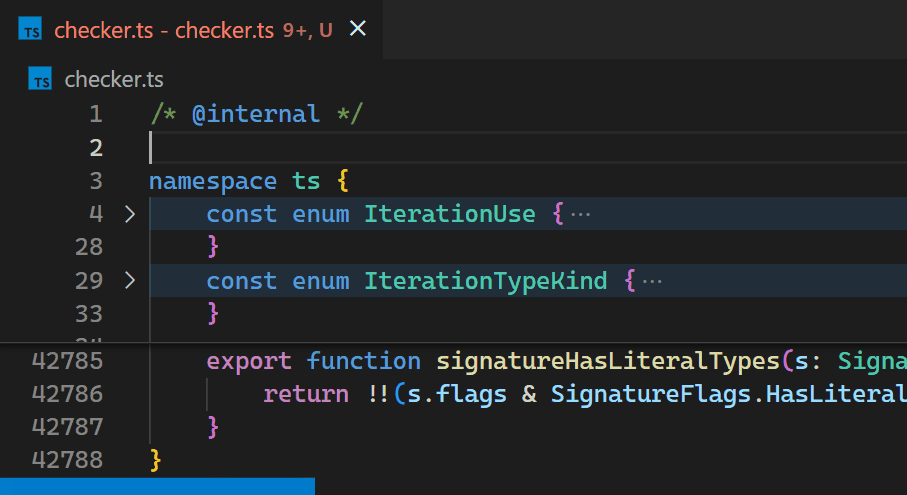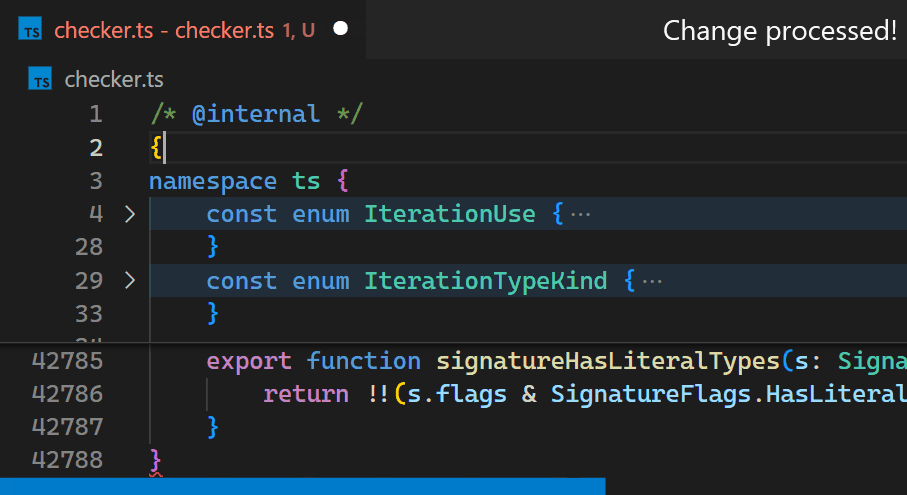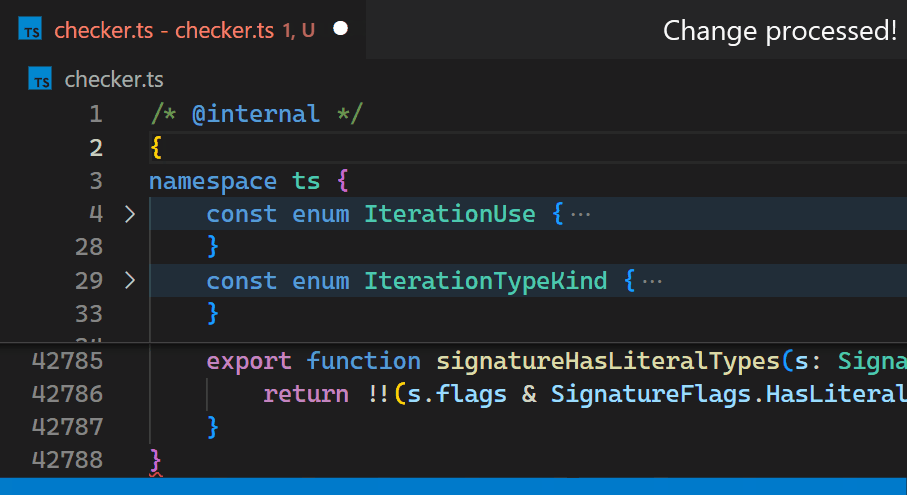
現在,更新不再明顯,即使對於具有數十萬個括號配對的檔案也是如此。請注意,在第 2 行中輸入 { 之後,第 42,788 行中的括號色彩會立即反映新的巢狀層級
一旦我們決定將其移至核心,我們也藉此機會研究如何盡可能加快速度。誰不喜歡演算法挑戰呢?
在不受限於公用 API 設計的情況下,我們可以利用 (2,3) 樹狀結構、無遞迴樹狀結構周遊、位元運算、增量剖析和其他技術,將擴充功能的在最壞情況下的更新 時間複雜度 (也就是當文件已開啟時,處理使用者輸入所需的時間) 從
此外,藉由重複使用轉譯器中的現有 Token 及其增量 Token 更新機制,我們獲得了另一個巨大的 (但恆定的) 速度提升。
適用於 Web 的 VS Code
除了效能更高之外,新的實作也支援 適用於 Web 的 VS Code,您可以在 vscode.dev 和 github.dev 中看到實際運作情況。由於 Bracket Pair Colorizer 2 重複使用 VS Code Token 引擎的方式,因此無法將擴充功能移轉成為我們所謂的 Web 擴充功能。
我們新的實作不僅適用於適用於 Web 的 VS Code,也直接適用於 Monaco Editor!
括號配對著色的挑戰
括號配對著色完全是為了快速判斷檢視區中的所有括號及其 (絕對) 巢狀層級。檢視區可以用文件中的行號和欄號範圍來描述,而且通常只是整個文件的一小部分。
不幸的是,括號的巢狀層級取決於所有在其之前的字元:將任何字元取代為左括號 "{" 通常會增加所有後續括號的巢狀層級。
因此,當最初在文件末尾著色括號時,必須處理整個文件的每個字元。

括號配對著色器擴充功能中的實作藉由在每次插入或移除單一個括號時,再次處理整個文件來解決此挑戰 (對於小型文件來說,這樣做非常合理)。然後必須移除色彩,並使用 VS Code Decoration API 重新套用色彩,這會將所有色彩裝飾傳送到轉譯器。
如先前所示,對於具有數十萬個括號配對以及同樣多的色彩裝飾的大型文件來說,這很慢。由於擴充功能無法以增量方式更新裝飾,而且必須一次全部取代,因此括號配對著色器擴充功能甚至無法做得更好。儘管如此,轉譯器仍以巧妙的方式 (透過使用所謂的 間隔樹狀結構) 組織所有這些裝飾,因此在收到 (可能數十萬個) 裝飾之後,轉譯速度始終很快。
我們的目標是不需要在每次按鍵時重新處理整個文件。相反地,處理單一文字編輯所需的時間應該只隨著文件長度以 (poly) 對數方式成長。
但是,我們仍然希望能夠在 (poly) 對數時間內查詢檢視區中的所有括號及其巢狀層級,就像使用 VS Code 的 Decoration API (使用上述間隔樹狀結構) 時的情況一樣。
演算法複雜度
您可以隨意跳過關於演算法複雜度的章節。
在以下內容中,
但是,我們允許
語言語意使括號配對著色變得困難
使括號配對著色真正困難的是偵測文件語言定義的實際括號。尤其是,我們不希望在註解或字串中偵測到左括號或右括號,如下列 C 範例所示
{ /* } */ char str[] = "}"; }
只有第三個出現的 "}" 才會封閉括號配對。
對於 Token 語言不規則的語言 (例如具有 JSX 的 TypeScript) 來說,這甚至更困難

位置 [1] 的括號是否與位置 [2] 或 [3] 的括號配對?這取決於範本字串常值運算式的長度,而只有具有不受限制狀態 (非規則 Tokenizer) 的 Tokenizer 才能正確判斷。
Token 來救援
幸好,語法醒目提示必須解決類似的問題:先前程式碼片段中位置 [2] 的括號應該轉譯為字串還是純文字?
事實證明,只要忽略語法醒目提示識別的註解和字串中的括號,就足以適用於大多數括號配對。< ... > 是我們目前發現唯一有問題的配對,因為這些括號通常同時用於比較和作為泛型類型的配對,同時具有相同的 Token 類型。
VS Code 已經有有效率且同步的機制來維護用於語法醒目提示的 Token 資訊,我們可以重複使用該機制來識別左括號和右括號。
這是 Bracket Pair Colorization 擴充功能的另一個挑戰,會對效能產生負面影響:它無法存取這些 Token,而且必須自行重新計算。關於如何有效率且可靠地向擴充功能公開 Token 資訊,我們思考了很久,但結論是,如果沒有大量洩漏到擴充功能 API 中的實作詳細資料,我們就無法做到這一點。因為擴充功能仍然必須傳送文件中每個括號的色彩裝飾清單,所以單獨使用 API 甚至無法解決效能問題。
附帶一提,當在文件開頭套用編輯,而該編輯會變更所有後續 Token 時 (例如,針對類似 C 的語言插入 /*),VS Code 不會一次重新 Token 化長文件,而是隨著時間推移分區塊進行。這可確保 UI 不會凍結,即使 Token 化在轉譯器中同步發生也是如此。
基本演算法
核心概念是使用 遞迴下降剖析器 來建置 抽象語法樹狀結構 (AST),描述所有括號配對的結構。當找到括號時,請檢查 Token 資訊,如果括號位於註解或字串中,則跳過括號。Tokenizer 允許剖析器預覽和讀取這類括號或文字 Token。
現在的訣竅是只儲存每個節點的長度 (以及擁有文字節點來涵蓋所有非括號的間隙),而不是儲存絕對開始/結束位置。只有長度可用時,仍然可以在 AST 中有效率地找到指定位置的括號節點。
下圖顯示具有長度註解的範例 AST

將此與使用絕對開始/結束位置的傳統 AST 表示法進行比較

這兩個 AST 描述的是相同的文件,但是當周遊第一個 AST 時,必須動態計算絕對位置 (這很容易做到),而在第二個 AST 中,絕對位置已經預先計算好。
但是,當在第一個樹狀結構中插入單一個字元時,只需要更新節點本身及其所有父節點的長度 - 所有其他長度都保持不變。
當絕對位置儲存在第二個樹狀結構中時,文件中每個後續節點的位置都必須遞增。
此外,藉由不儲存絕對位移,可以共用具有相同長度的葉節點,以避免配置。
以下說明如何在 TypeScript 中定義具有長度註解的 AST
type Length = ...;
type AST = BracketAST | BracketPairAST | ListAST | TextAST;
/** Describes a single bracket, such as `{`, `}` or `begin` */
class BracketAST {
constructor(public length: Length) {}
}
/** Describes a matching bracket pair and the node in between, e.g. `{...}` */
class BracketPairAST {
constructor(
public openingBracket: BracketAST;
public child: BracketPairAST | ListAST | TextAST;
public closingBracket: BracketAST;
) {}
length = openingBracket.length + child.length + closingBracket.length;
}
/** Describes a list of bracket pairs or text nodes, e.g. `()...()` */
class ListAST {
constructor(
public items: Array<BracketPairAST | TextAST>
) {}
length = items.sum(item => item.length);
}
/** Describes text that has no brackets in it. */
class TextAST {
constructor(public length: Length) {}
}
查詢這類 AST 以列出檢視區中的所有括號及其巢狀層級相對簡單:執行深度優先周遊、動態計算目前節點的絕對位置 (方法是新增先前節點的長度),並跳過完全在要求範圍之前或之後的節點子系。
此基本演算法已經可以運作,但仍有一些未解決的問題
- 我們如何確保查詢給定範圍內的所有括號都具有所需的對數效能?
- 輸入時,我們如何避免從頭開始建構新的 AST?
- 我們如何處理 Token 區塊更新?當開啟大型文件時,Token 最初不可用,但會以區塊方式逐區塊傳入。
確保查詢時間為對數時間
查詢給定範圍內的括號時,會降低效能的原因是過長的清單:我們無法對其子系執行快速二元搜尋,以跳過所有不相關的不相交節點,因為我們需要加總每個節點的長度,才能動態計算絕對位置。在最壞的情況下,我們需要逐一查看所有節點。
在以下範例中,我們必須查看 13 個節點 (藍色),才能找到位置 24 的括號

雖然我們可以計算和快取長度總和以啟用二元搜尋,但這與儲存絕對位置有相同的問題:每次單一節點成長或縮小時,我們都需要重新計算所有長度總和,這對於非常長的清單來說成本很高。
相反地,我們允許清單將其他清單作為子系
class ListAST {
constructor(public items: Array<ListAST | BracketPairAST | TextAST>) {}
length = items.sum(item => item.length);
}
這如何改善情況?
如果我們可以確保每個清單只有有限數量的子系,而且類似於對數高度的平衡樹狀結構,那麼事實證明,這足以獲得查詢括號所需的對數效能。
保持清單樹狀結構平衡
我們使用 (2,3) 樹狀結構 來強制執行這些清單的平衡:每個清單必須至少有 2 個且最多有 3 個子系,而且清單的所有子系在平衡清單樹狀結構中都必須具有相同的高度。請注意,括號配對在平衡樹狀結構中被視為高度為 0 的葉節點,但它在 AST 中可能會有子系。
當在初始化期間從頭開始建構 AST 時,我們會先收集所有子系,然後將它們轉換為這類平衡樹狀結構。這可以在線性時間內完成。
先前範例的可能 (2,3) 樹狀結構可能如下所示。請注意,我們現在只需要查看 8 個節點 (藍色),即可找到位置 24 的括號配對,而且清單是否有 2 個或 3 個子系存在一些自由度

最壞情況複雜度分析
您可以隨意跳過關於演算法複雜度的章節。
目前,我們假設每個清單都類似於 (2,3) 樹狀結構,因此最多有 3 個子系。
為了最大化查詢時間,我們查看具有
{
{
... O(log N) many nested bracket pairs
{
{} [1]
}
...
}
}
尚未涉及任何清單,但我們已經需要周遊
現在,針對最壞情況,我們填滿文件,直到文件大小為
{}{}{}{}{}{}{}{}... O(N / log N) many
{
{}{}{}{}{}{}{}{}... O(N / log N) many
{
... O(log N) many nested bracket pairs
{
{}{}{}{}{}{}{}{}... O(N / log N) many
{} [1]
}
...
}
}
相同巢狀層級上的每個括號清單都會產生高度為
的樹狀結構。因此,若要找到位置 [1] 的節點,我們必須周遊
因此,查詢括號的最壞情況時間複雜度為
此外,這也顯示 AST 的最大高度為
增量更新
效能括號配對著色最有趣的問題仍然懸而未決:在給定目前的 (平衡) AST 和取代特定範圍的文字編輯的情況下,我們如何有效率地更新樹狀結構以反映文字編輯?
這個想法是重複使用用於初始化的遞迴下降剖析器,並新增快取策略,以便可以重複使用和跳過不受文字編輯影響的節點。
當遞迴下降剖析器剖析位置的括號配對清單時
以下範例顯示當插入單個左括號時,哪些節點可以重複使用(綠色標示)(省略個別括號節點)

在透過重新解析包含編輯的節點並重複使用所有未變更的節點來處理文字編輯後,更新後的 AST 如下所示。 請注意,所有 11 個可重複使用的節點都可以透過消耗 3 個節點 B、H 和 G 來重複使用,並且只有 4 個節點必須重新建立(橘色標示)

此範例證明,平衡列表不僅使查詢速度更快,而且還有助於一次重複使用大量節點區塊。
演算法複雜度
您可以隨意跳過關於演算法複雜度的章節。
讓我們假設文字編輯替換了大小最多為
我們只需要重新解析與編輯範圍相交的節點。 因此,最多
顯然,如果一個節點沒有與編輯範圍相交,那麼它的任何子節點也不會相交。 因此,我們只需要考慮重複使用不與編輯範圍相交,但其父節點相交的節點(這將隱含地重複使用節點及其父節點都不與編輯範圍相交的所有節點)。 此外,此類父節點不能完全被編輯範圍覆蓋,否則它們的所有子節點都將與編輯範圍相交。 但是,AST 中的每個層級最多只有兩個節點與編輯範圍部分相交。 由於 AST 最多有
因此,為了建構更新後的樹狀結構,我們需要重新解析最多
這也將決定更新操作的時間複雜度,但有一個注意事項。
我們如何重新平衡 AST?
不幸的是,上一個範例中的樹狀結構不再平衡。
當將重複使用的列表節點與新解析的節點組合時,我們必須做一些工作來維護 (2,3) 樹的屬性。 我們知道重複使用和新解析的節點都已經是 (2,3) 樹,但它們可能具有不同的高度 - 因此我們不能只是建立父節點,因為 (2,3) 樹節點的所有子節點都必須具有相同的高度。
我們如何有效地將所有這些高度混合的節點串連成單個 (2,3) 樹?
這可以輕鬆簡化為將較小的樹狀結構前置或附加到較大的樹狀結構的問題:如果兩棵樹具有相同的高度,則建立一個包含兩個子節點的列表就足夠了。 否則,我們將高度為
因為這具有執行時間
為了平衡先前範例中的列表 α 和 γ,我們對其子節點執行串連操作(紅色列表違反 (2,3) 樹屬性,橘色節點具有意外的高度,綠色節點在重新平衡時重新建立)

由於列表 B 在不平衡樹狀結構中的高度為 2,而括號對 β 的高度為 0,因此我們需要將 β 附加到 B,並完成列表 α。 剩下的 (2,3) 樹是 B,因此它成為新的根節點並取代列表 α。 繼續處理 γ,其子節點 δ 和 H 的高度為 0,而 G 的高度為 1。
我們先串連 δ 和 H,並建立一個新的高度為 1 的父節點 Y(因為 δ 和 H 具有相同的高度)。 然後我們串連 Y 和 G,並建立一個新的父列表 X(原因相同)。 然後 X 成為父括號對的新子節點,取代不平衡的列表 γ。
在範例中,平衡操作有效地將最頂層列表的高度從 3 降低到 2。 但是,AST 的總高度從 4 增加到 5,這對最壞情況的查詢時間產生負面影響。 這是由括號對 β 引起的,它在平衡列表樹中充當葉節點,但實際上包含另一個高度為 2 的列表。
在平衡父列表時考慮 β 的內部 AST 高度可能會改善最壞情況,但會脫離 (2,3) 樹的理論。
演算法複雜度
您可以隨意跳過關於演算法複雜度的章節。
我們必須串連最多
由於串連兩個不同高度的節點具有時間複雜度
我們如何有效地尋找可重複使用的節點?
我們有兩個資料結構來完成此任務:編輯前位置對應器和節點讀取器。
位置對應器 盡可能將新文件(套用編輯後)中的位置對應到舊文件(套用編輯前)。 它還告訴我們目前位置和下一個編輯位置之間的長度(如果我們處於編輯狀態,則為 0)。 這是以
的時間複雜度完成。 當處理文字編輯並解析節點時,此元件會為我們提供一個我們可以潛在重複使用的節點的位置,以及此節點可以擁有的最大長度 - 顯然,我們要重複使用的節點必須短於到下一個編輯位置的距離。
節點讀取器 可以快速找到 AST 中給定位置滿足給定謂詞的最長節點。 為了找到我們可以重複使用的節點,我們使用位置對應器來查找其舊位置及其允許的最大長度,然後使用節點讀取器來尋找此節點。 如果我們找到這樣的節點,我們就知道它沒有變更,可以重複使用它並跳過其長度。
由於節點讀取器是使用單調遞增的位置進行查詢,因此它不必每次都從頭開始搜尋,而是可以從上次重複使用的節點的末尾開始搜尋。 關鍵在於無遞迴的樹狀結構遍歷演算法,它可以深入節點,但也可以跳過它們或返回父節點。 當找到可重複使用的節點時,遍歷停止並繼續處理下一個節點讀取器請求。
單次查詢節點讀取器的複雜度最高為
Token 更新
當在不包含文字 */ 的長 C 樣式文件的開頭插入 /* 時,整個文件會變成單個註解,並且所有語彙基元都會變更。
由於語彙基元是在渲染器程序中同步計算的,因此無法一次重新語彙基元化而不凍結 UI。
相反,語彙基元會隨著時間推移分批更新,以便 JavaScript 事件迴圈不會被封鎖太長時間。 雖然這種方法不會減少總封鎖時間,但它提高了更新期間 UI 的回應能力。 相同的機制也用於最初語彙基元化文件時。
幸運的是,由於括號對 AST 的增量更新機制,我們可以透過將更新視為單個文字編輯來立即套用此類批次語彙基元更新,該編輯將重新語彙基元化的範圍替換為自身。 一旦所有語彙基元更新都傳入,即使使用者在重新語彙基元化正在進行時編輯文件,括號對 AST 也保證處於與從頭開始建立時相同的狀態。
這樣一來,即使文件中的所有語彙基元都變更,不僅語彙基元化效能良好,而且括號對著色也是如此。
但是,當文件在註解中包含大量不平衡的括號時,當括號對解析器學習到應忽略這些括號時,文件末尾的括號顏色可能會閃爍。
為了避免在開啟文件並導航到文件末尾時括號對顏色閃爍,我們維護兩個括號對 AST,直到初始語彙基元化程序完成。 第一個 AST 是在沒有語彙基元資訊的情況下建置的,並且不接收語彙基元更新。 第二個 AST 最初是第一個 AST 的複製品,但接收語彙基元更新,並隨著語彙基元化進展和語彙基元更新的套用而越來越發散。 最初,第一個 AST 用於查詢括號,但一旦文件完全語彙基元化,第二個 AST 就會接管。
由於深度複製幾乎與重新解析文件一樣昂貴,因此我們實作了寫入時複製,從而在
長度編碼
的時間複雜度內實現複製。 編輯器視圖使用行號和欄號描述視窗。 顏色裝飾也應表示為基於行/欄的範圍。
為了避免在偏移量和基於行/欄的位置之間進行轉換(這可以在
請注意,這種方法與直接按行索引的資料結構(例如使用字串陣列來描述文件的行內容)顯著不同。 特別是,這種方法可以在行之間和行內進行單次二元搜尋。
新增兩個這樣的長度很容易,但需要區分大小寫:雖然行計數是直接相加的,但只有當第二個長度跨越零行時,才包含第一個長度的欄計數。
令人驚訝的是,大多數程式碼都不需要知道長度是如何表示的。 只有位置對應器變得更加複雜,因為必須注意單行可以包含多個文字編輯。
作為實作細節,我們將此類長度編碼為單個數字,以減少記憶體壓力。 JavaScript 支援高達
進一步的困難:未封閉的括號配對
到目前為止,我們假設所有括號對都是平衡的。 但是,我們也希望支援未封閉和未開啟的括號對。 遞迴下降剖析器的優點在於,我們可以使用錨點集來改善錯誤復原。
考慮以下範例
( [1]
} [2]
) [3]
顯然,[2] 的 } 不會封閉任何括號對,並且表示未開啟的括號。 [1] 和 [3] 的括號匹配良好。 但是,當在文件開頭插入 { 時,情況會發生變化
{ [0]
( [1]
} [2]
) [3]
現在,[0] 和 [2] 應該匹配,而 [1] 是未封閉的括號,[3] 是未開啟的括號。
特別是,在以下範例中,[1] 應該是終止於 [2] 之前的未封閉括號
{
( [1]
} [2]
{}
否則,開啟括號可能會變更不相關的後續括號對的巢狀層級。
為了支援這種錯誤復原,可以使用錨點集來追蹤呼叫端可以繼續使用的預期語彙基元集。 在上一個範例中的位置 [1],錨點集將為} } 時,它不會消耗它,而是傳回未封閉的括號對。
在第一個範例中,[2] 的錨點集為) }。 因為它不是錨點集的一部分,所以它被報告為未開啟的括號。
在重複使用節點時,需要考慮到這一點:當在其前面加上 { 時,不能重複使用配對 ( } )。 我們使用位元集來編碼錨點集,並計算每個節點的包含未開啟括號的集合。 如果它們相交,我們就不能重複使用該節點。 幸運的是,括號類型只有幾種,因此這不會對效能產生太大影響。
展望未來
高效的括號對著色是一項有趣的挑戰。 借助新的資料結構,我們還可以更有效率地解決與括號對相關的其他問題,例如 一般括號匹配 或 顯示彩色行範圍。
即使 JavaScript 可能不是編寫高效能程式碼的最佳語言,但透過降低漸近演算法複雜度,尤其是在處理大型輸入時,仍然可以獲得很大的速度提升。
祝您編碼愉快!
Henning Dieterichs,VS Code 團隊成員 @hediet_dev