VS Code Data Wrangler 入門指南
Data Wrangler 是一種以程式碼為中心的資料檢視與清理工具,已整合至 VS Code 和 VS Code Jupyter Notebook 中。它提供豐富的使用者介面來檢視和分析您的資料、顯示具洞察力的欄位統計資料與視覺化效果,並在您清理和轉換資料時自動產生 Pandas 程式碼。
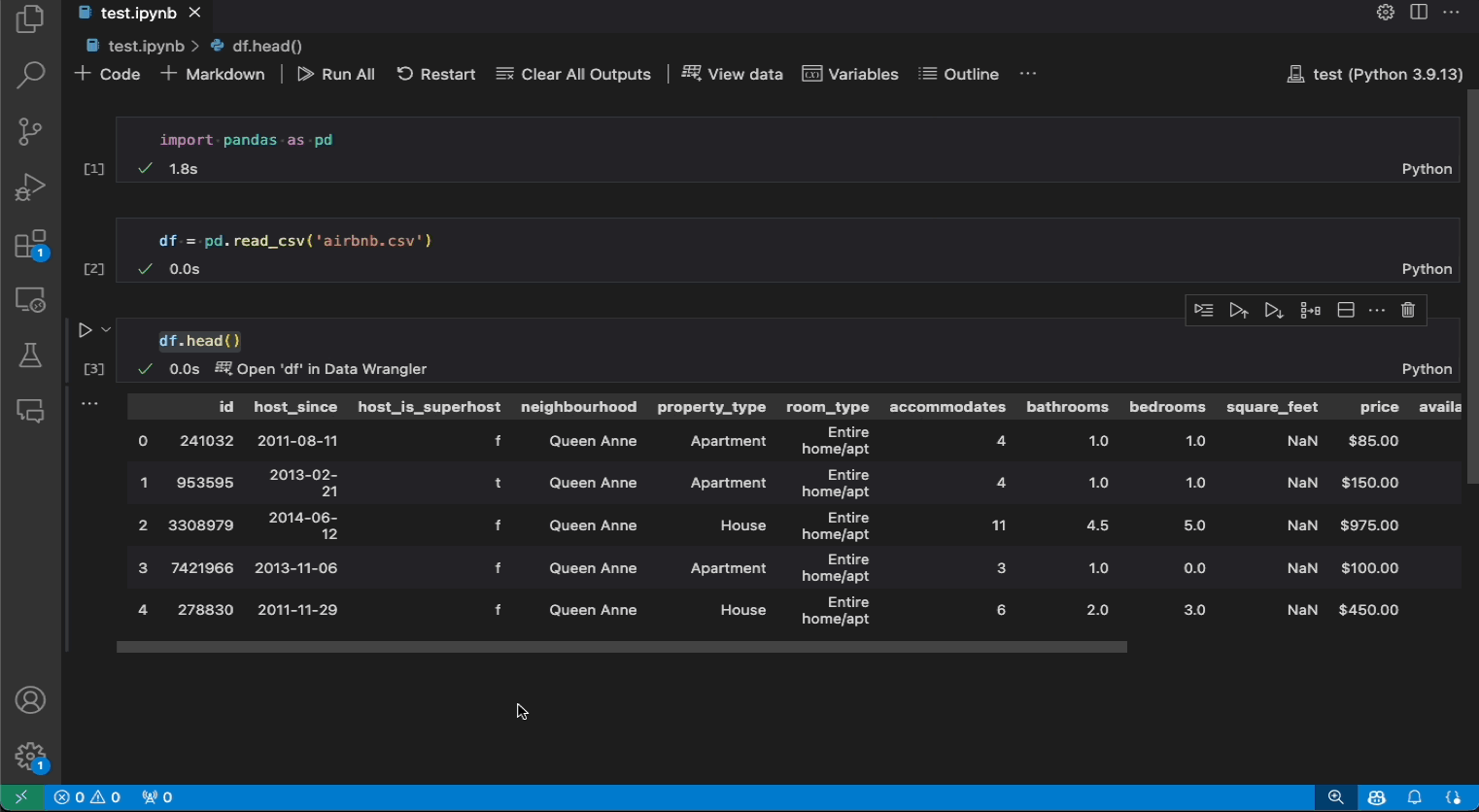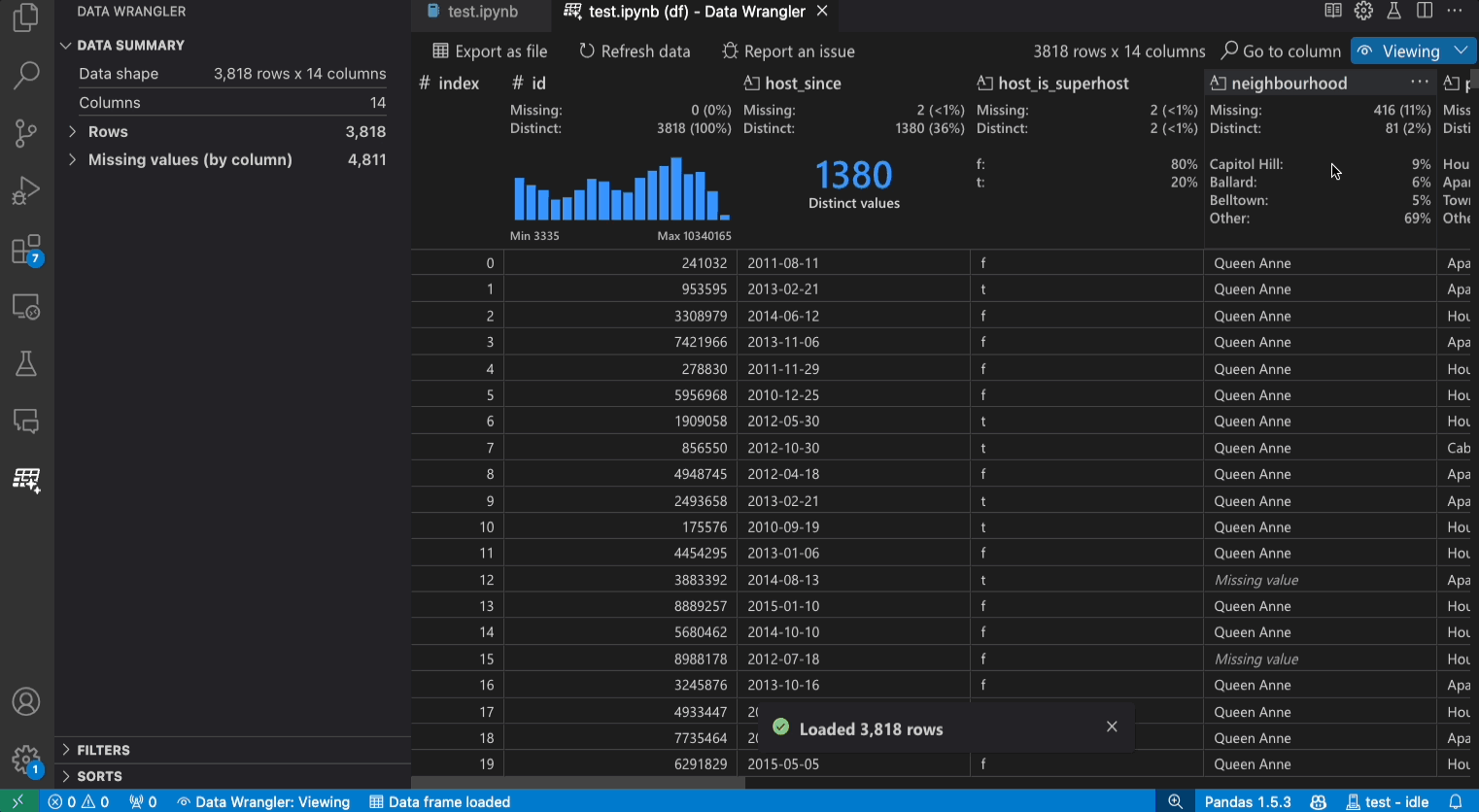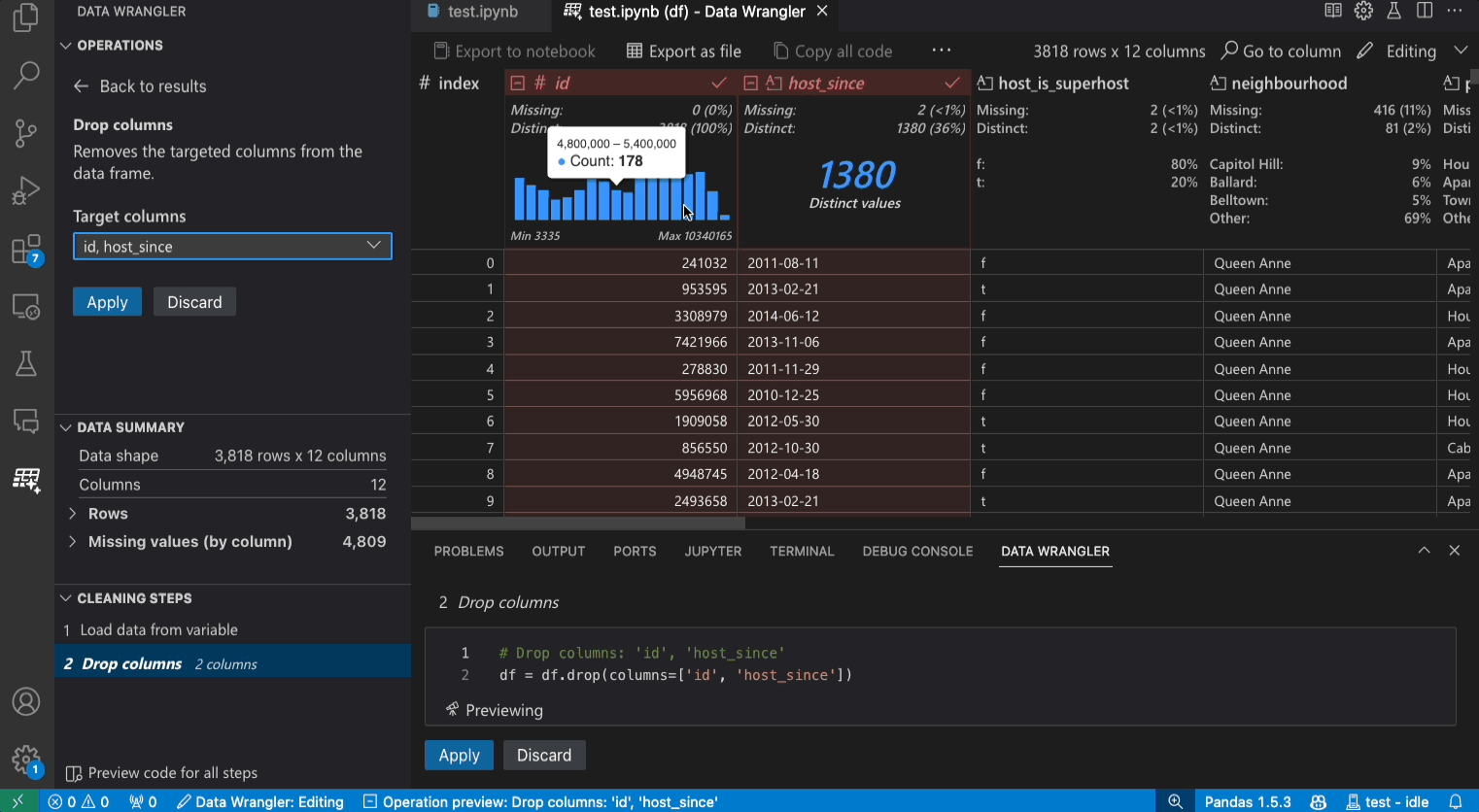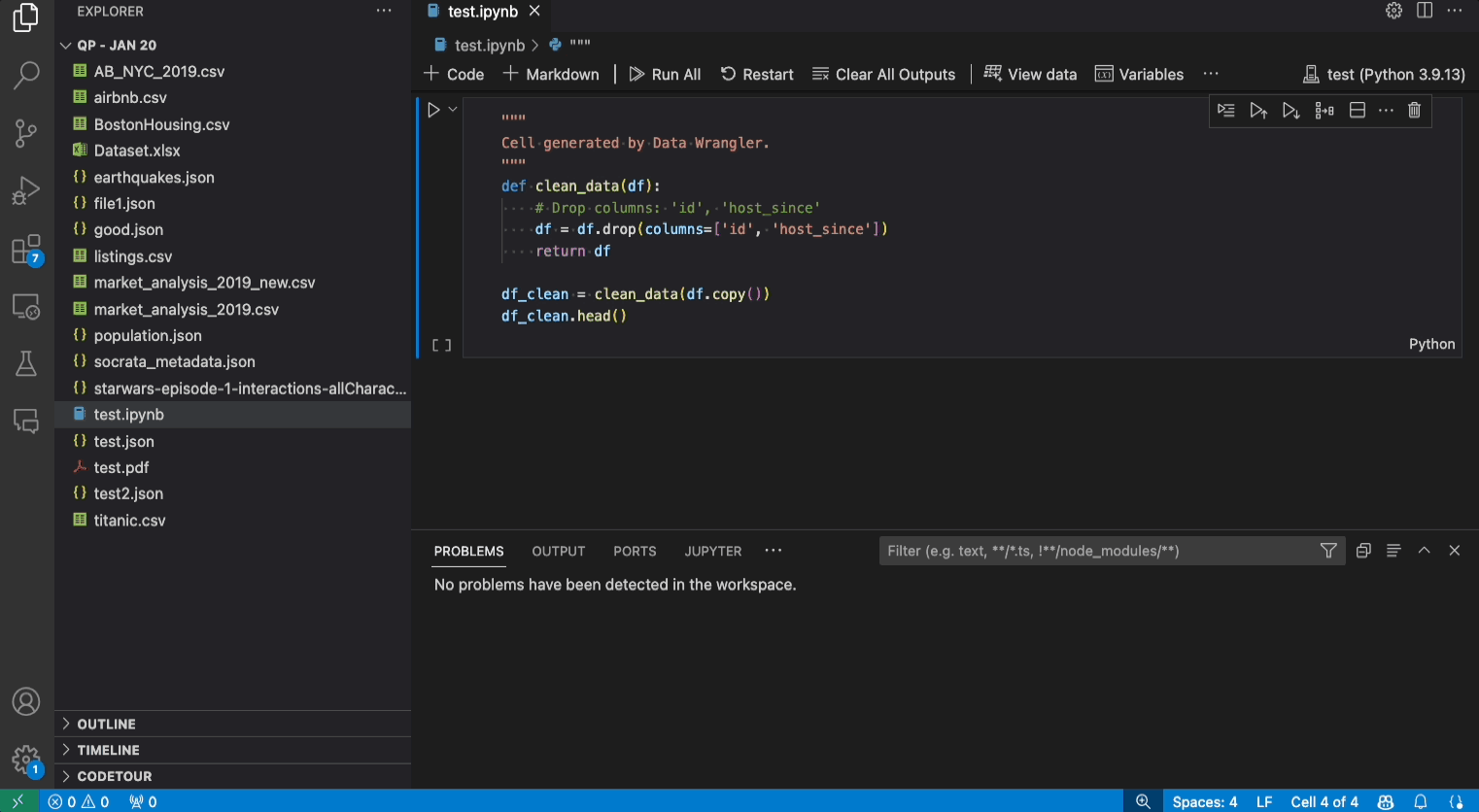
以下是從 Notebook 開啟 Data Wrangler 以使用內建操作分析和清理資料的範例。然後,自動產生的程式碼會匯出回 Notebook 中。
本文涵蓋如何
- 安裝與設定 Data Wrangler
- 從 Notebook 啟動 Data Wrangler
- 從資料檔案啟動 Data Wrangler
- 使用 Data Wrangler 探索您的資料
- 使用 Data Wrangler 對您的資料執行操作與清理
- 編輯與匯出資料整理程式碼至 Notebook
- 疑難排解與提供意見反應
設定您的環境
- 如果您尚未安裝 Python,請立即安裝。重要事項:Data Wrangler 僅支援 Python 3.8 或更高版本。
- 安裝 Visual Studio Code。
- 安裝 Data Wrangler 擴充功能
當您第一次啟動 Data Wrangler 時,它會詢問您想要連線到哪個 Python 核心。它也會檢查您的機器和環境,以查看是否已安裝必要的 Python 套件,例如 Pandas。
以下列出 Python 和 Python 套件的必要版本,以及它們是否由 Data Wrangler 自動安裝
| 名稱 | 最低必要版本 | 自動安裝 |
|---|---|---|
| Python | 3.8 | 否 |
| pandas | 0.25.2 | 是 |
如果在您的環境中找不到這些相依性,Data Wrangler 將嘗試使用 pip 為您安裝。如果 Data Wrangler 無法安裝相依性,最簡單的解決方法是手動執行 pip install,然後重新啟動 Data Wrangler。Data Wrangler 需要這些相依性,以便它可以產生 Python 和 Pandas 程式碼。
開啟 Data Wrangler
當您在 Data Wrangler 中時,您都處於沙箱環境中,這表示您可以安全地探索和轉換資料。除非您明確匯出變更,否則原始資料集不會被修改。
從 Jupyter Notebook 啟動 Data Wrangler
有三種方法可以從您的 Jupyter Notebook 啟動 Data Wrangler
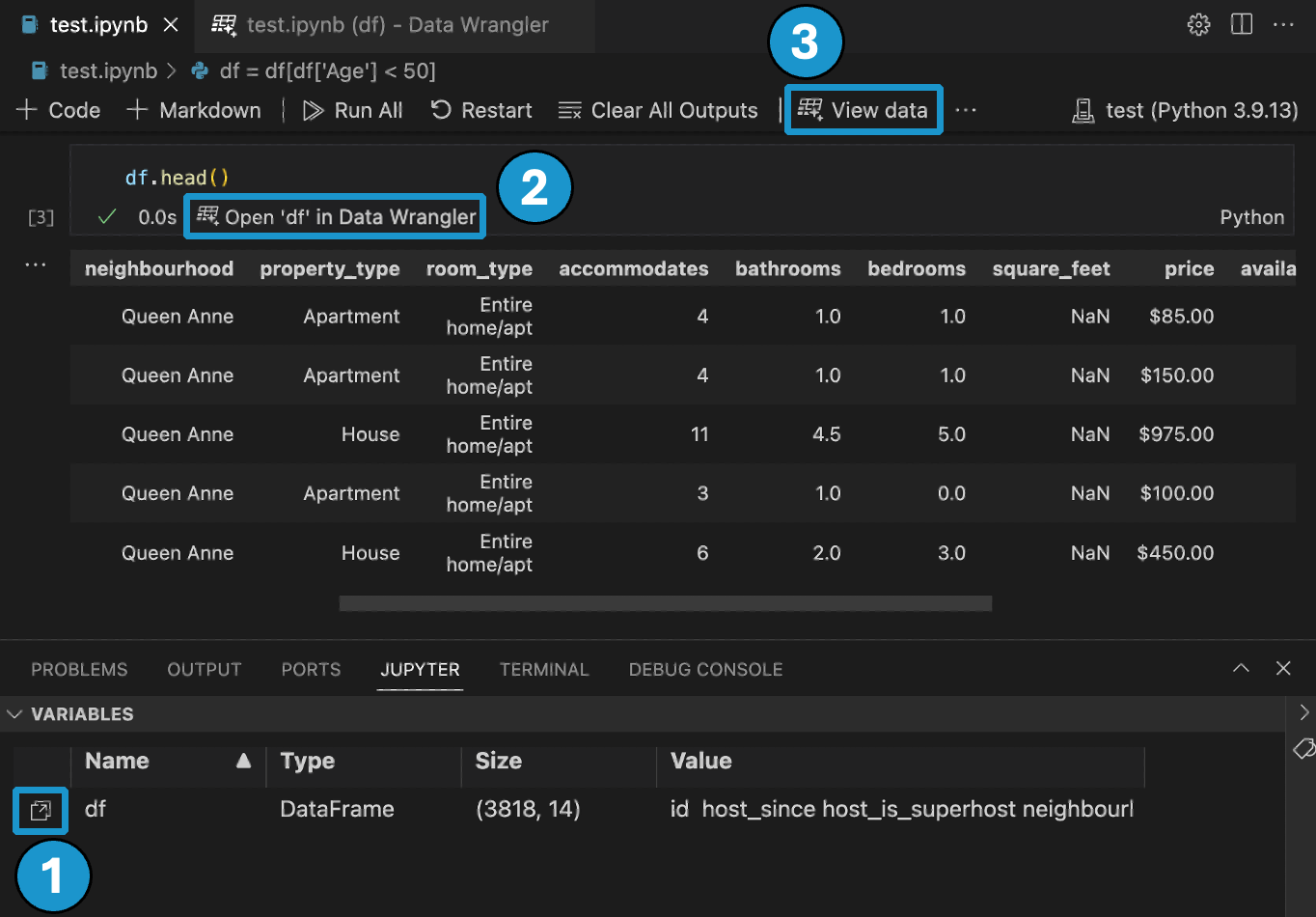
- 在 [Jupyter] > [變數] 面板中,在任何支援的資料物件旁邊,您都可以看到一個啟動 Data Wrangler 的按鈕。
- 如果您的 Notebook 中有 Pandas 資料框架,您現在可以在執行程式碼輸出資料框架後,在儲存格底部看到 [在 Data Wrangler 中開啟 'df'] 按鈕(其中 'df' 是資料框架的變數名稱)。這包括 1)
df.head()、2)df.tail()、3)display(df)、4)print(df)、5)df。 - 在 Notebook 工具列中,選取 [檢視資料] 會顯示 Notebook 中每個支援的資料物件的清單。然後您可以選擇要 Data Wrangler 中開啟的清單中的哪個變數。
直接從檔案啟動 Data Wrangler
您也可以直接從本機檔案(例如 .csv)啟動 Data Wrangler。若要執行此操作,請在 VS Code 中開啟任何包含您想要開啟之檔案的資料夾。在 [檔案總管] 檢視中,以滑鼠右鍵按一下檔案,然後按一下 [在 Data Wrangler 中開啟]。
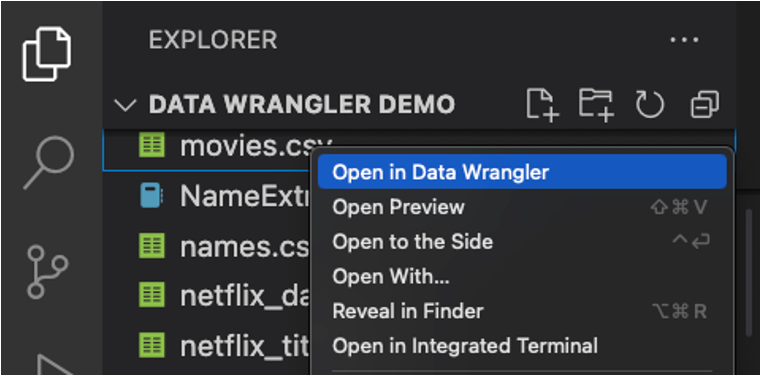
Data Wrangler 目前支援下列檔案類型
.csv/.tsv.xls/.xlsx.parquet
根據檔案類型,您可以指定檔案的分隔符號和/或工作表。
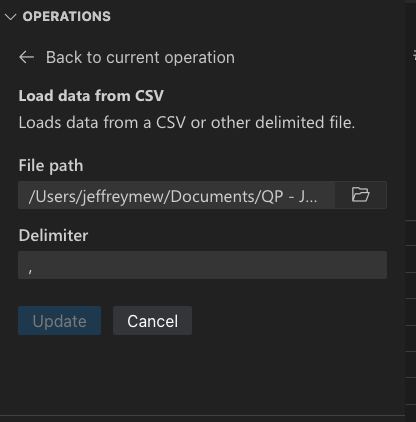
您也可以設定預設使用 Data Wrangler 開啟這些檔案類型。
UI 導覽
Data Wrangler 在處理您的資料時有兩種模式。每種模式的詳細資訊將在以下章節中說明。
- 檢視模式:檢視模式最佳化介面,讓您可以快速檢視、篩選和排序資料。此模式非常適合對資料集進行初始探索。
- 編輯模式:編輯模式最佳化介面,讓您可以對資料集套用轉換、清理或修改。當您在介面中套用這些轉換時,Data Wrangler 會自動產生相關的 Pandas 程式碼,並且可以匯出回您的 Notebook 以供重複使用。
注意:依預設,Data Wrangler 會在檢視模式中開啟。您可以在設定編輯器中變更此行為 。

檢視模式介面
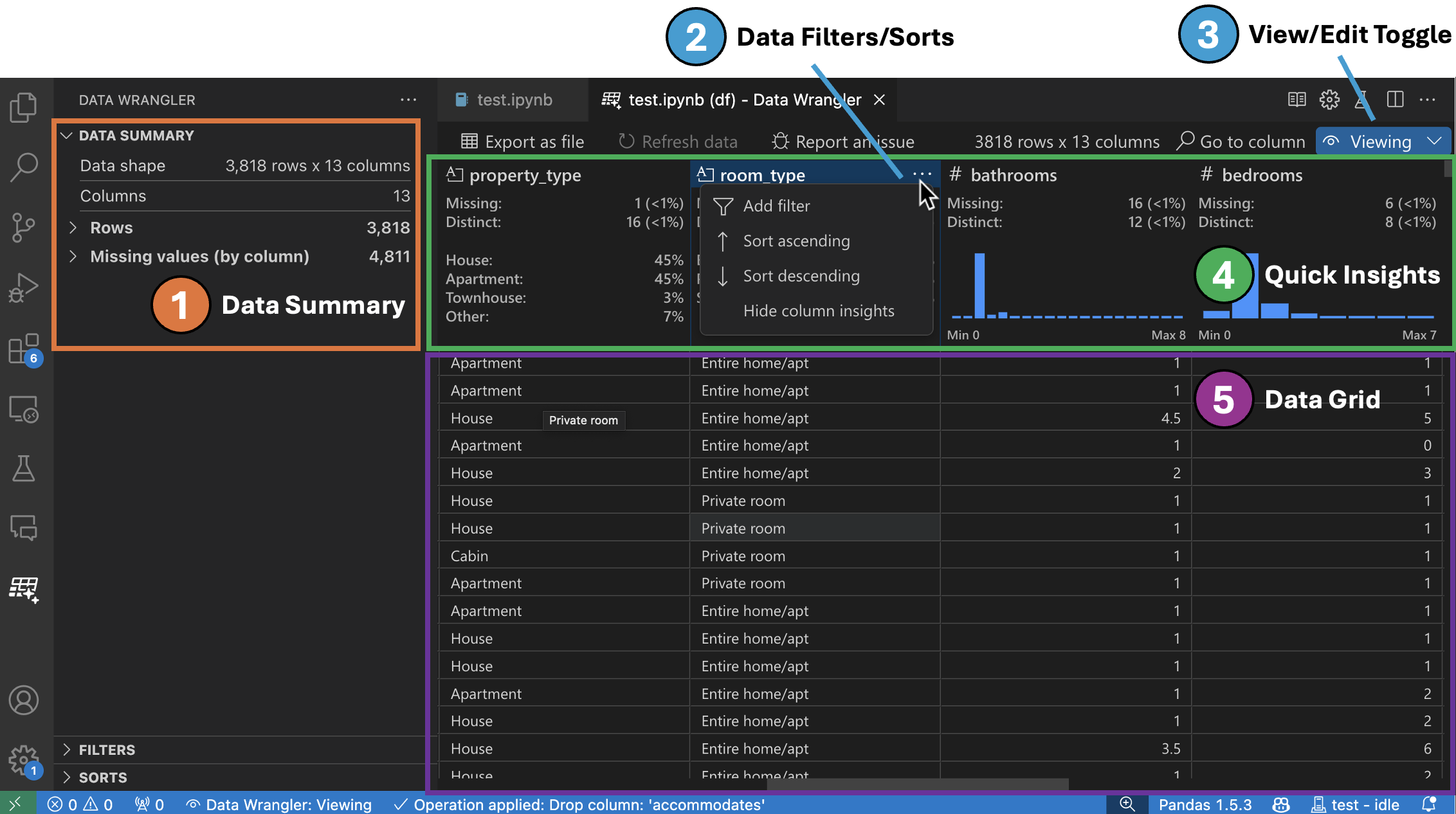
-
[資料摘要] 面板會顯示您的整體資料集或特定欄位的詳細摘要統計資料 (如果已選取欄位)。
-
您可以從欄位的標頭選單中對欄位套用任何 [資料篩選器/排序]。
-
在 Data Wrangler 的 [檢視] 或 [編輯] 模式之間切換,以存取內建的資料操作。
-
[快速洞察] 標頭中,您可以快速查看每個欄位的寶貴資訊。根據欄位的資料類型,快速洞察會顯示資料的分佈或資料點的頻率,以及遺失值和相異值。
-
資料格線提供您一個可捲動的窗格,您可以在其中檢視整個資料集。
編輯模式介面
切換到編輯模式會在 Data Wrangler 中啟用其他功能和使用者介面元素。在以下螢幕擷取畫面中,我們使用 Data Wrangler 將最後一欄中的遺失值取代為該欄位的中位數。
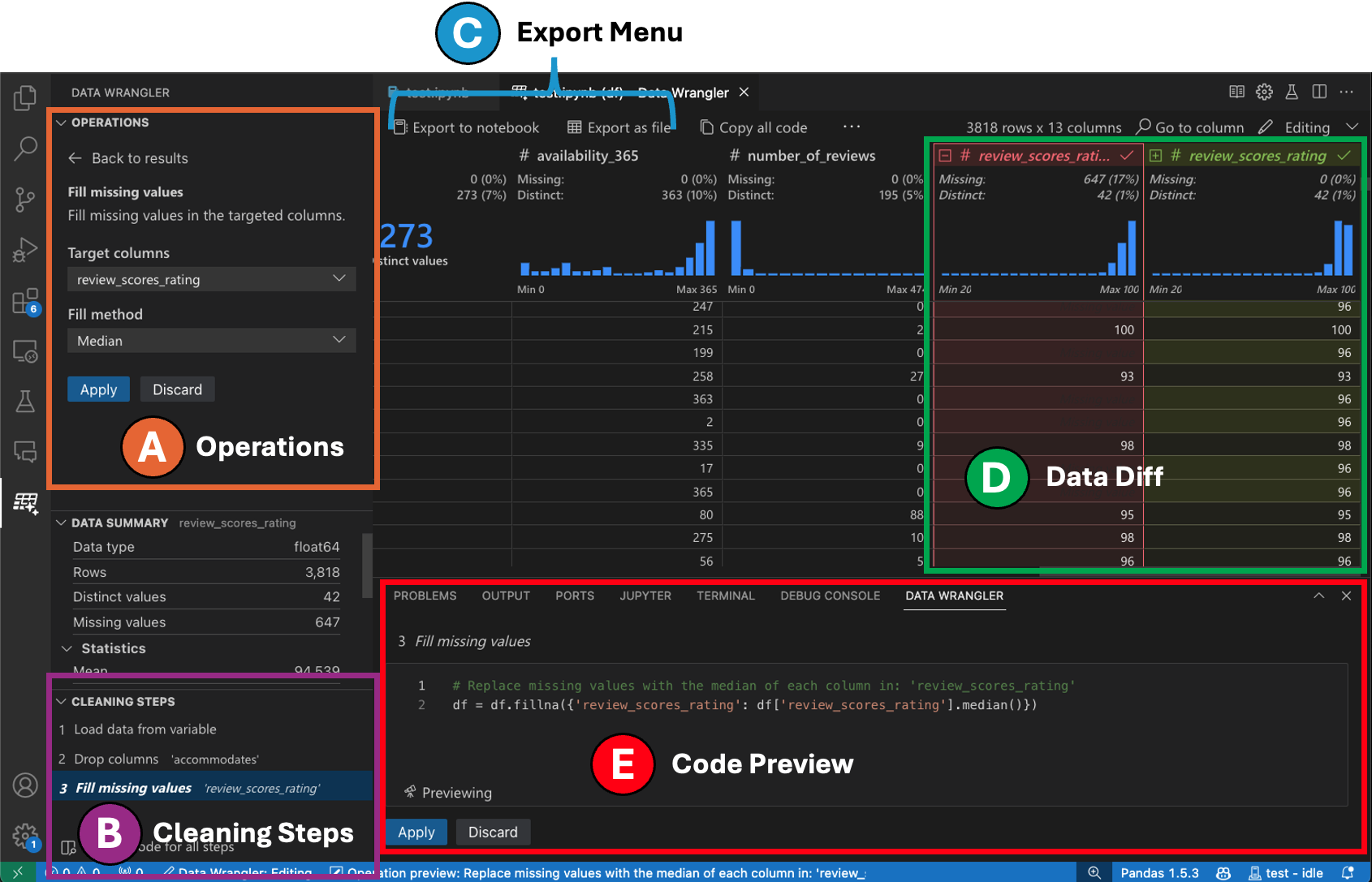
-
[操作] 面板中,您可以搜尋 Data Wrangler 的所有內建資料操作。這些操作依類別組織。
-
[清理步驟] 面板會顯示先前已套用的所有操作的清單。它讓使用者可以復原特定操作或編輯最近的操作。選取步驟將會醒目提示資料差異檢視中的變更,並顯示與該操作相關聯的產生的程式碼。
-
[匯出] 選單可讓您將程式碼匯出回 Jupyter Notebook,或將資料匯出到新檔案。
-
當您選取操作並預覽其對資料的影響時,格線會覆蓋資料差異檢視,顯示您對資料所做的變更。
-
[程式碼預覽] 區段會顯示在選取操作時 Data Wrangler 產生的 Python 和 Pandas 程式碼。當未選取任何操作時,它會保持空白。您可以編輯產生的程式碼,這會導致資料格線醒目提示對資料的影響。
Data Wrangler 操作
內建的 Data Wrangler 操作可以從 [操作] 面板中選取。
下表列出 Data Wrangler 初始版本目前支援的 Data Wrangler 操作。我們計劃在不久的將來新增更多操作。
| 操作 | 描述 |
|---|---|
| 排序 | 以遞增或遞減順序排序欄位 |
| 篩選 | 根據一或多個條件篩選列 |
| 計算文字長度 | 建立新欄位,其值等於文字欄位中每個字串值的長度 |
| 獨熱編碼 | 將類別資料分割成每個類別的新欄位 |
| 多標籤二元化器 | 使用分隔符號將類別資料分割成每個類別的新欄位 |
| 從公式建立欄位 | 使用自訂 Python 公式建立欄位 |
| 變更欄位類型 | 變更欄位的資料類型 |
| 捨棄欄位 | 刪除一或多個欄位 |
| 選取欄位 | 選擇要保留的一或多個欄位,並刪除其餘欄位 |
| 重新命名欄位 | 重新命名一或多個欄位 |
| 複製欄位 | 建立一或多個欄位的複本 |
| 捨棄遺失值 | 移除具有遺失值的列 |
| 捨棄重複列 | 捨棄在一或多個欄位中具有重複值的所有列 |
| 填滿遺失值 | 將具有遺失值的儲存格取代為新值 |
| 尋找與取代 | 將儲存格取代為相符的模式 |
| 依欄位分組並彙總 | 依欄位分組並彙總結果 |
| 移除空白字元 | 從文字的開頭和結尾移除空白字元 |
| 分割文字 | 根據使用者定義的分隔符號將欄位分割成多個欄位 |
| 第一個字元大寫 | 將第一個字元轉換為大寫,其餘字元轉換為小寫 |
| 將文字轉換為小寫 | 將文字轉換為小寫 |
| 將文字轉換為大寫 | 將文字轉換為大寫 |
| 字串轉換範例 | 當從您提供的範例中偵測到模式時,自動執行字串轉換 |
| DateTime 格式化範例 | 當從您提供的範例中偵測到模式時,自動執行 DateTime 格式化 |
| 新欄位範例 | 當從您提供的範例中偵測到模式時,自動建立欄位。 |
| 縮放最小值/最大值 | 在最小值和最大值之間縮放數值欄位 |
| 四捨五入 | 將數字四捨五入到指定的小數位數 |
| 向下捨入 (floor) | 將數字向下捨入到最接近的整數 |
| 向上捨入 (ceiling) | 將數字向上捨入到最接近的整數 |
| 自訂操作 | 根據範例和現有欄位的衍生自動建立新欄位 |
如果缺少您希望 Data Wrangler 支援的操作,請在我們的 Data Wrangler GitHub 存放庫中提交功能要求。
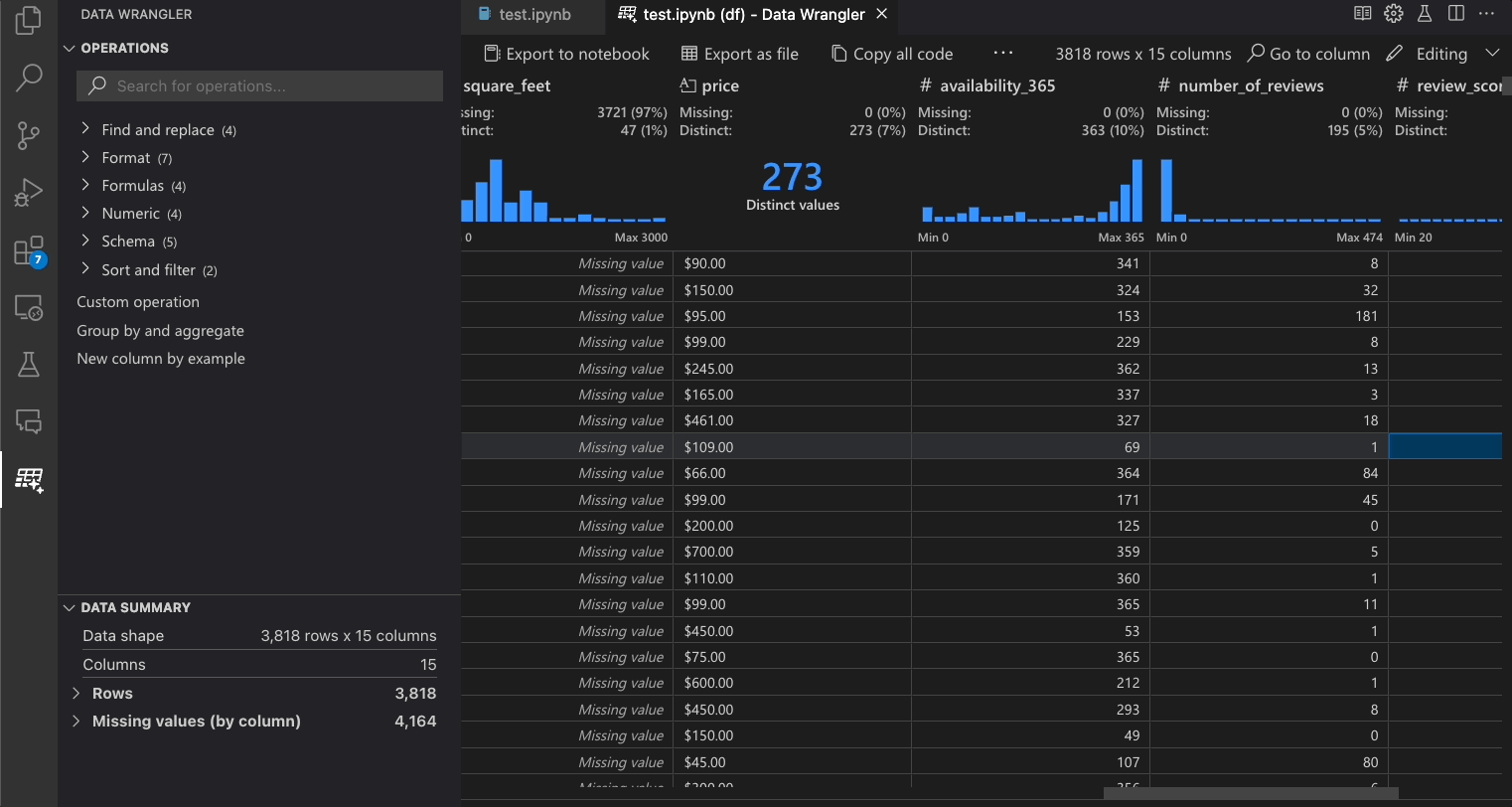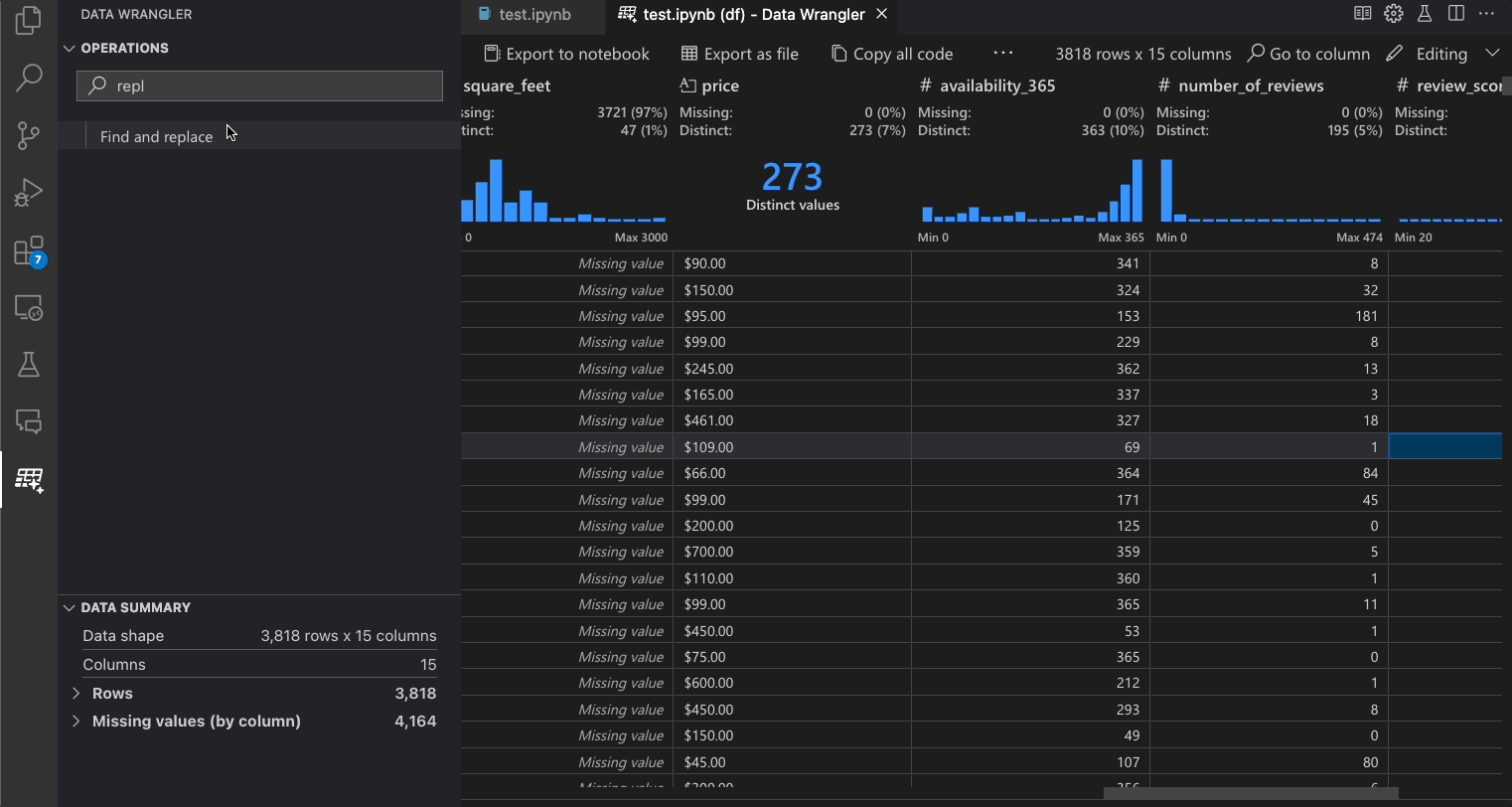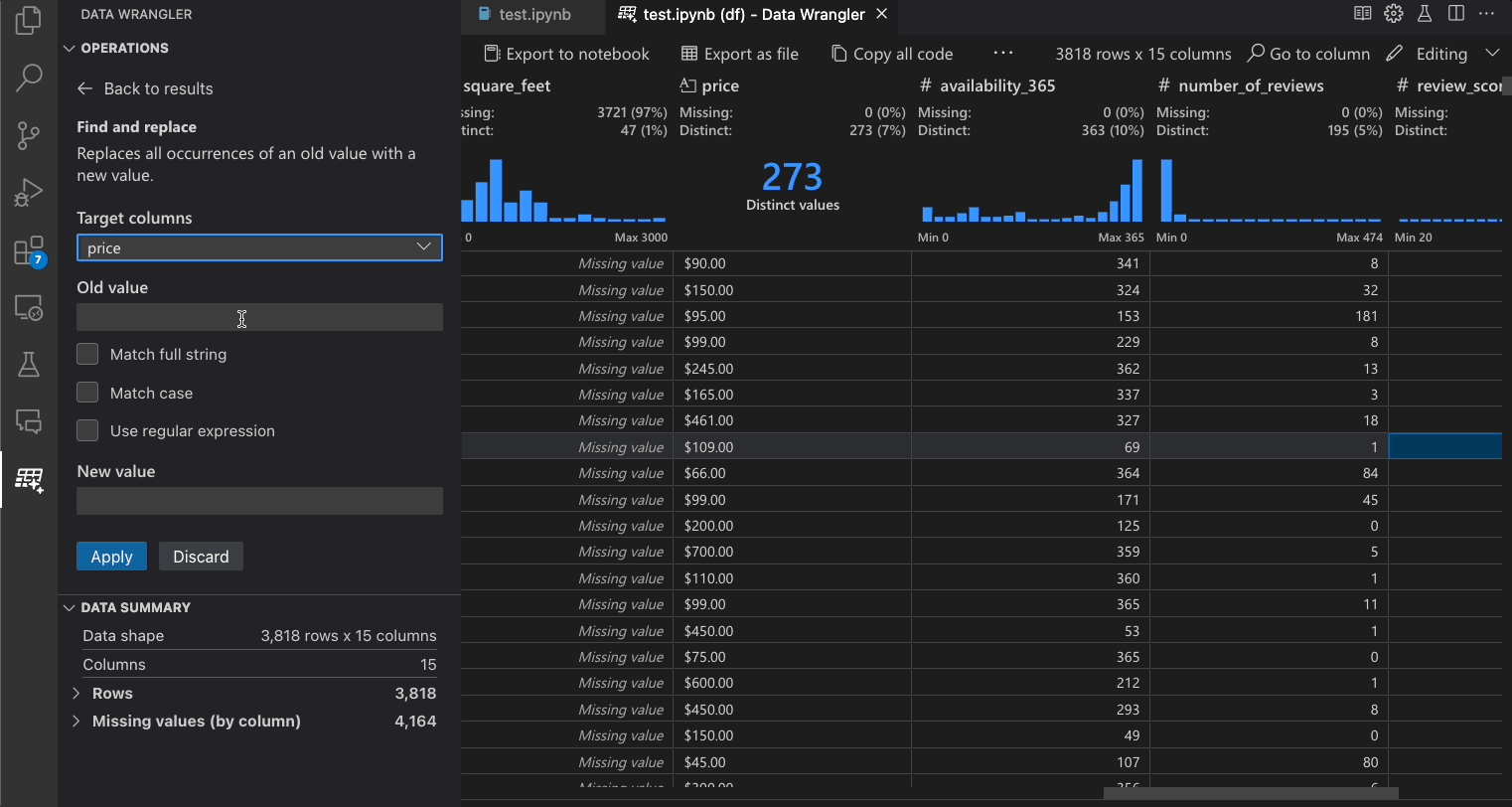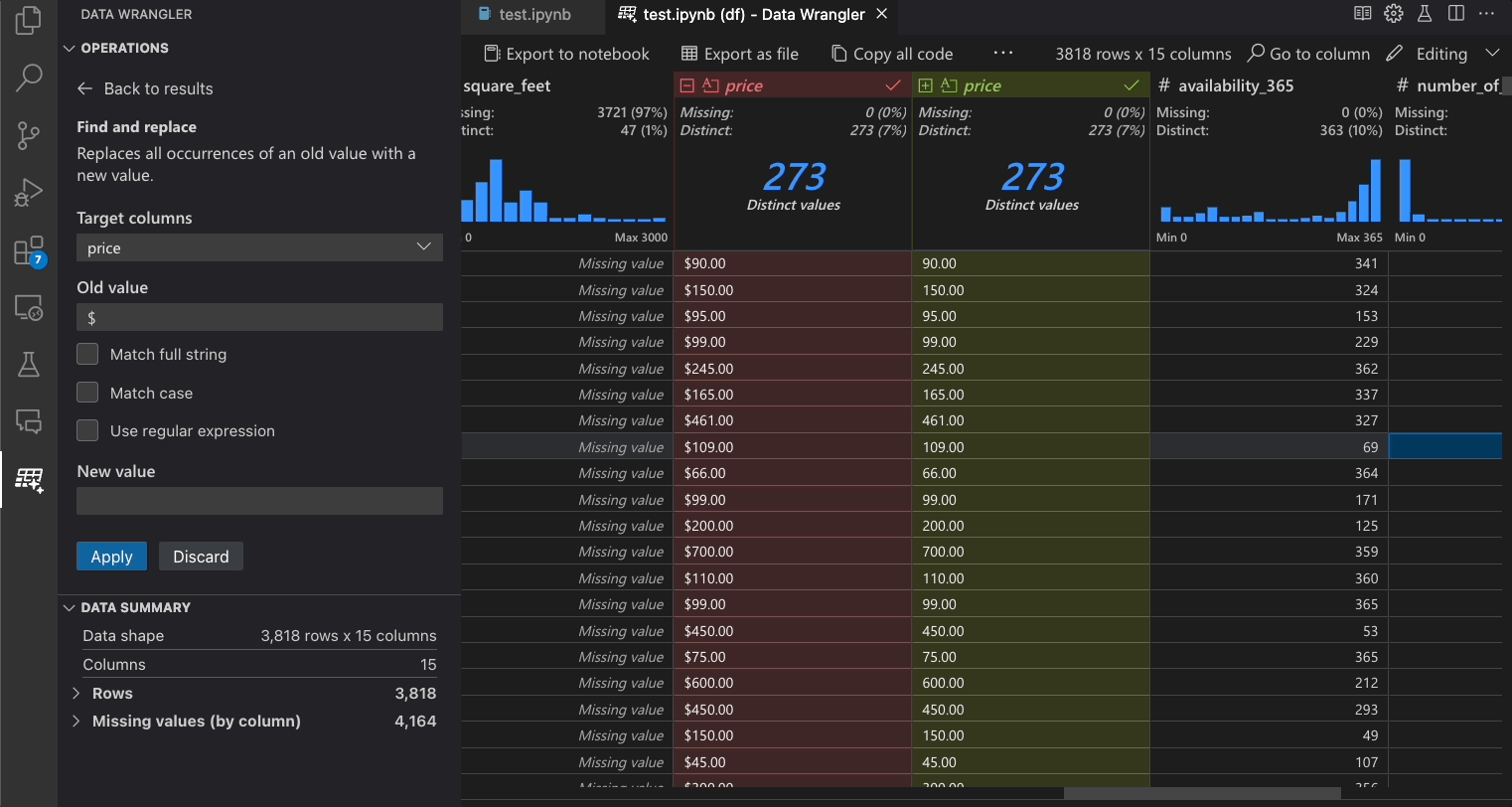
修改先前的步驟
產生的程式碼的每個步驟都可以透過 [清理步驟] 面板修改。首先,選取您要修改的步驟。然後,當您變更操作 (透過程式碼或操作面板) 時,您對資料所做的變更效果會在格線檢視中醒目提示。
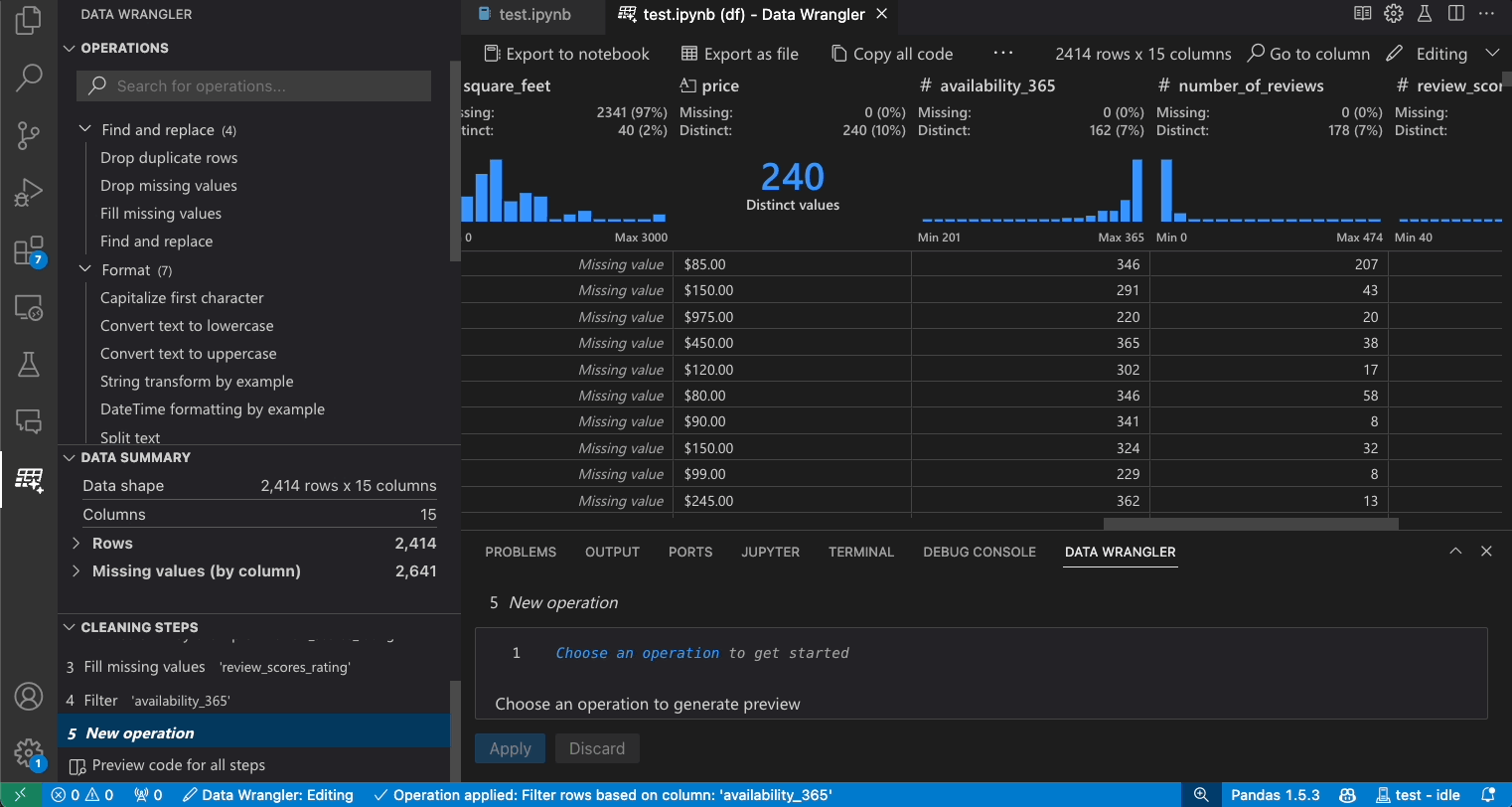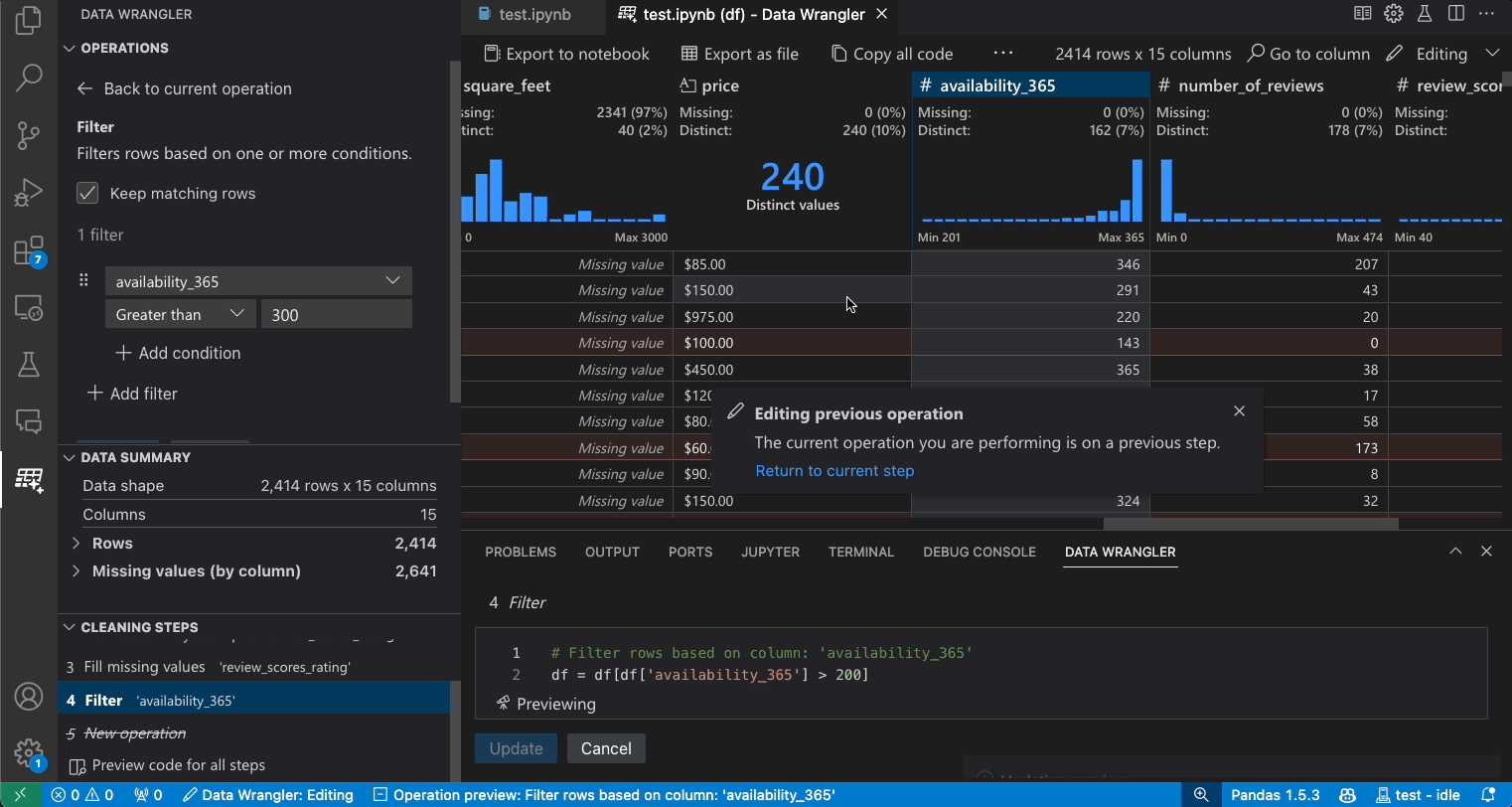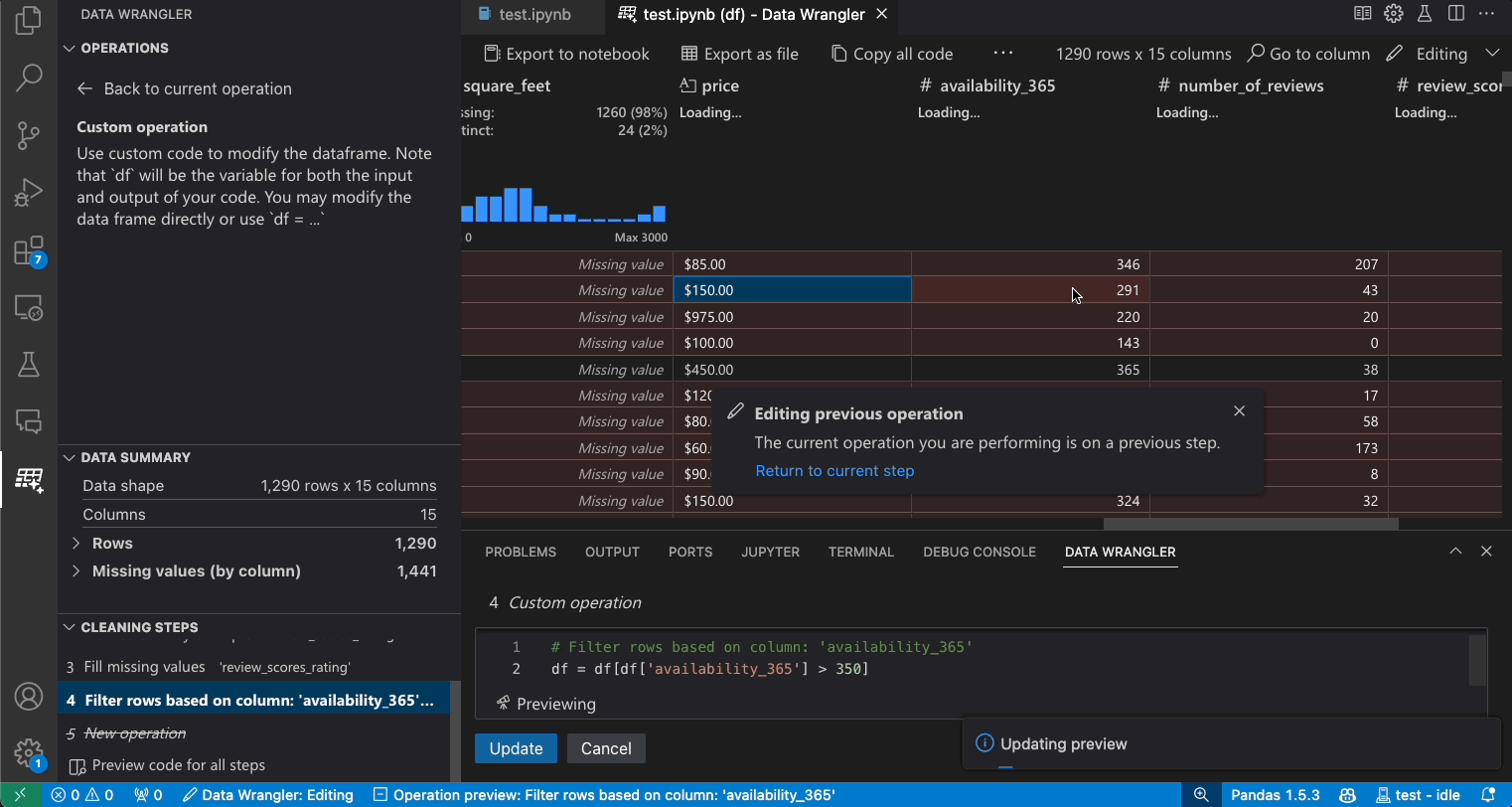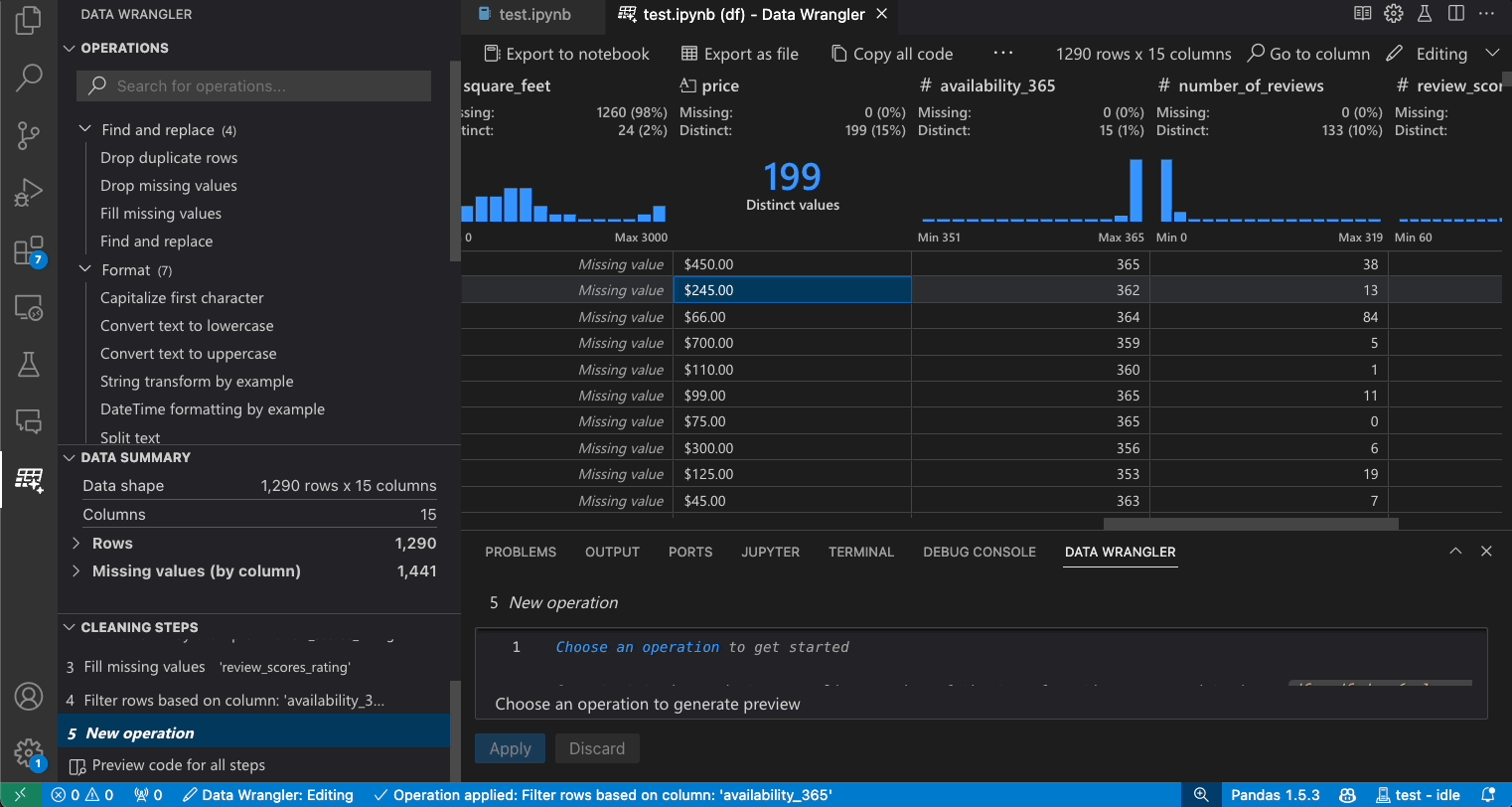
編輯與匯出程式碼
在 Data Wrangler 中完成資料清理步驟後,有三種方法可以從 Data Wrangler 匯出清理後的資料集。
- 匯出程式碼回 Notebook 並結束:這會在您的 Jupyter Notebook 中建立一個新儲存格,其中包含您產生的所有資料清理程式碼,並封裝成 Python 函式。
- 將資料匯出到檔案:這會將清理後的資料集儲存為您電腦上的新 CSV 或 Parquet 檔案。
- 複製程式碼到剪貼簿:這會複製 Data Wrangler 為資料清理操作產生的所有程式碼。
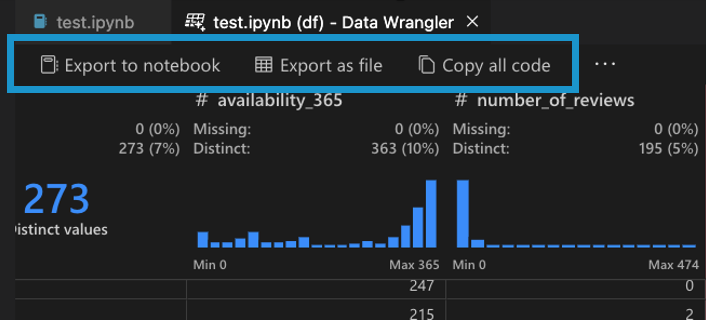
搜尋欄位
若要在您的資料集中尋找特定欄位,請從 Data Wrangler 工具列中選取 [前往欄位],然後搜尋相關欄位。
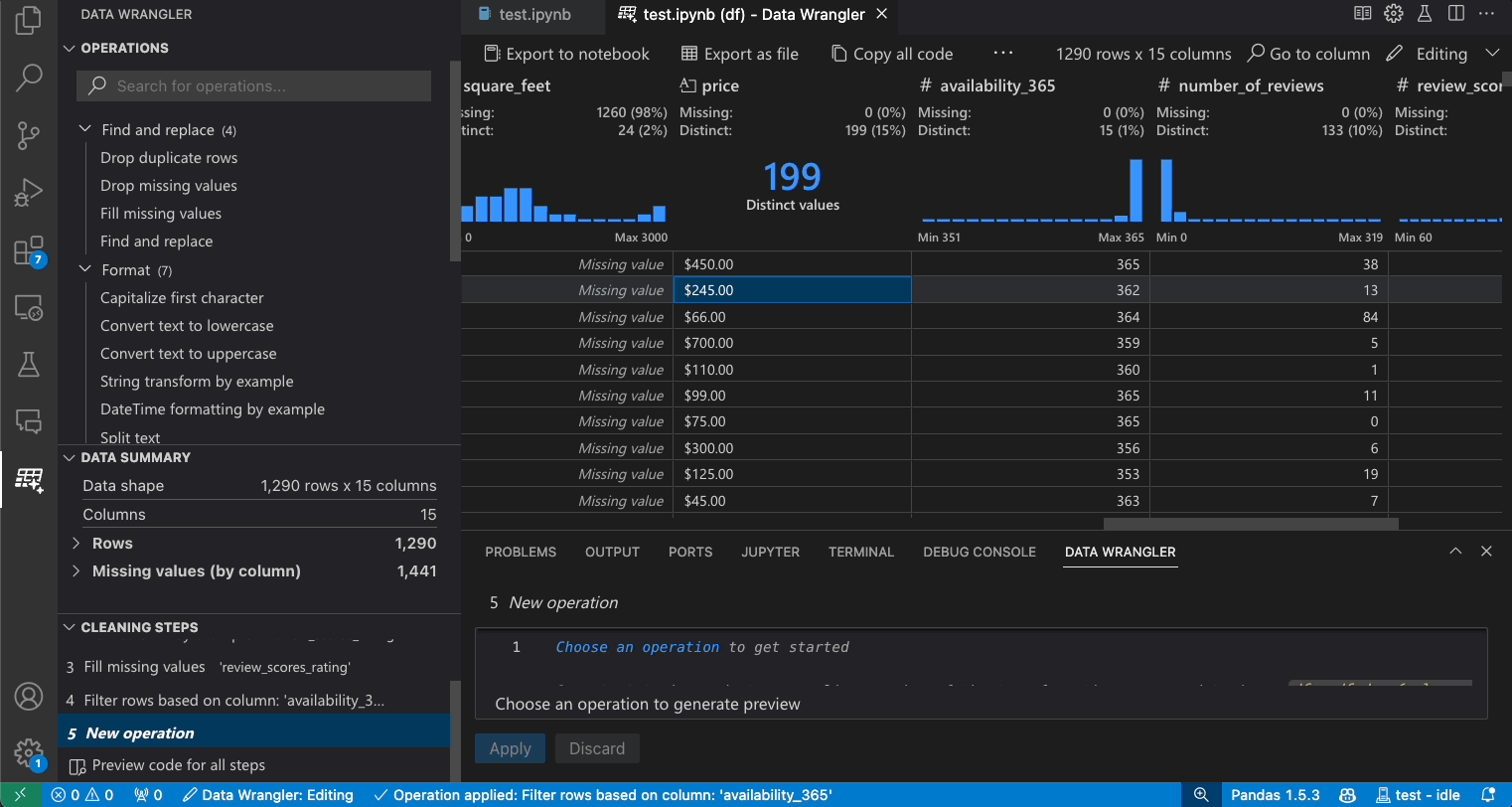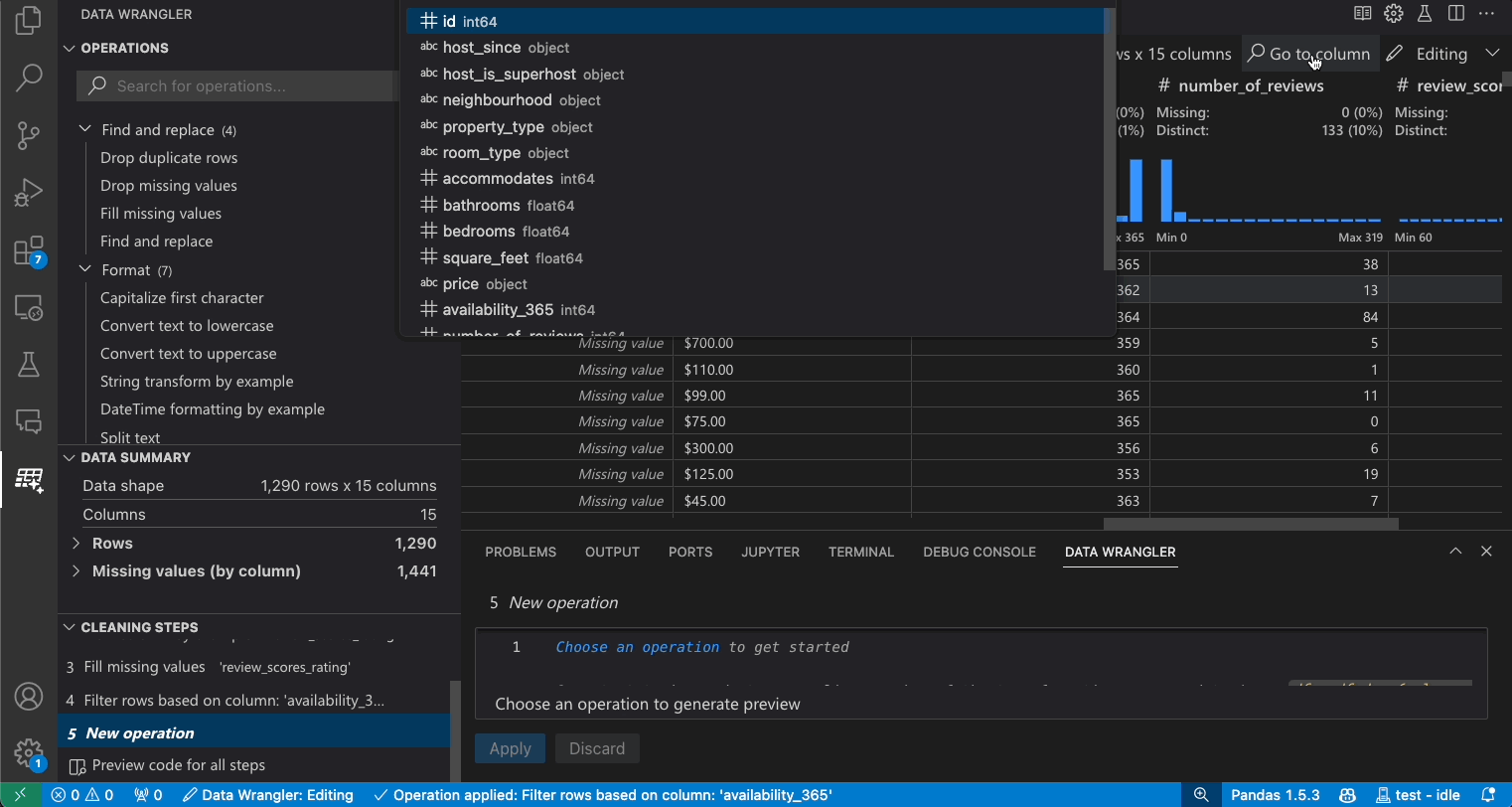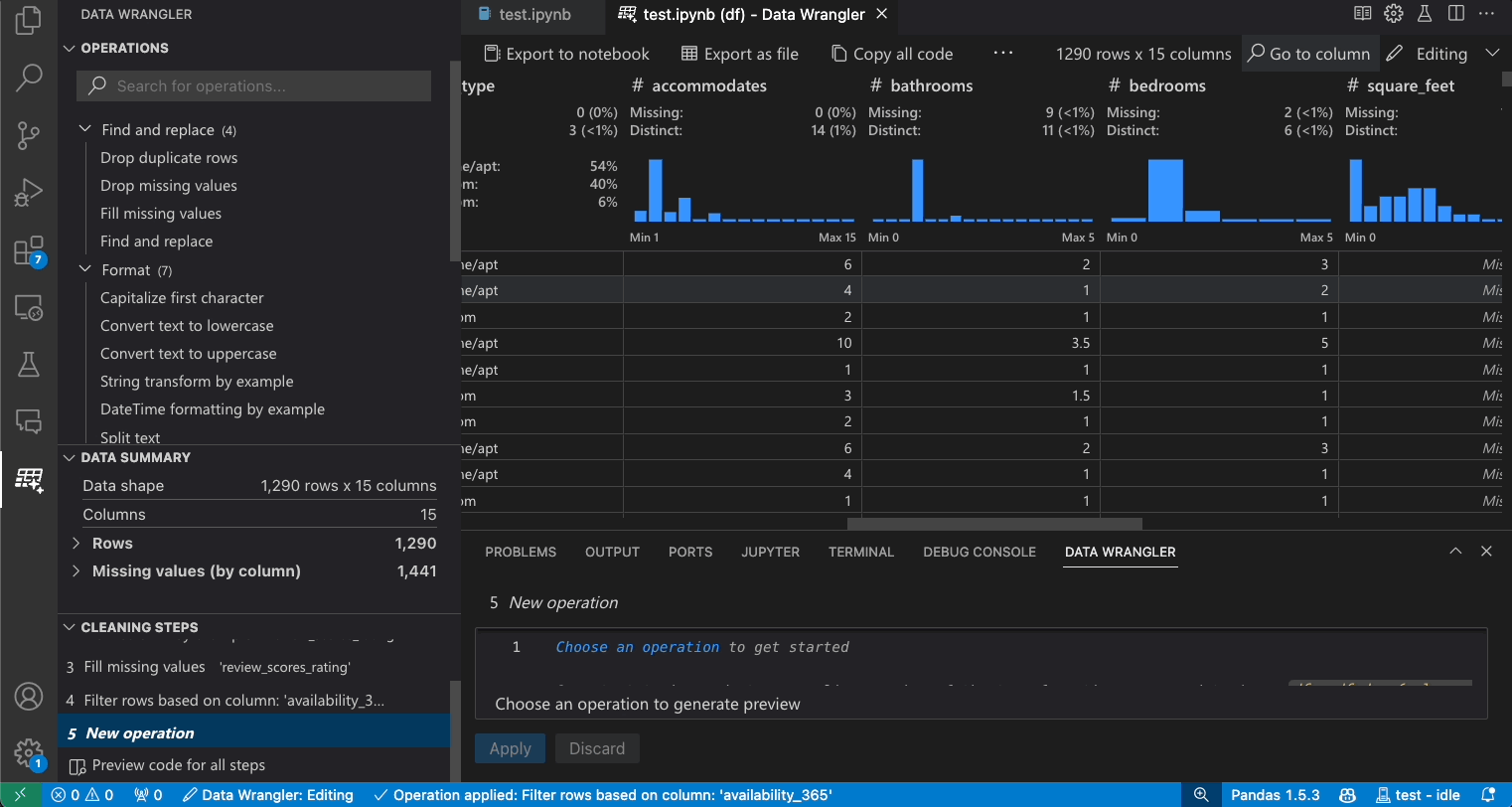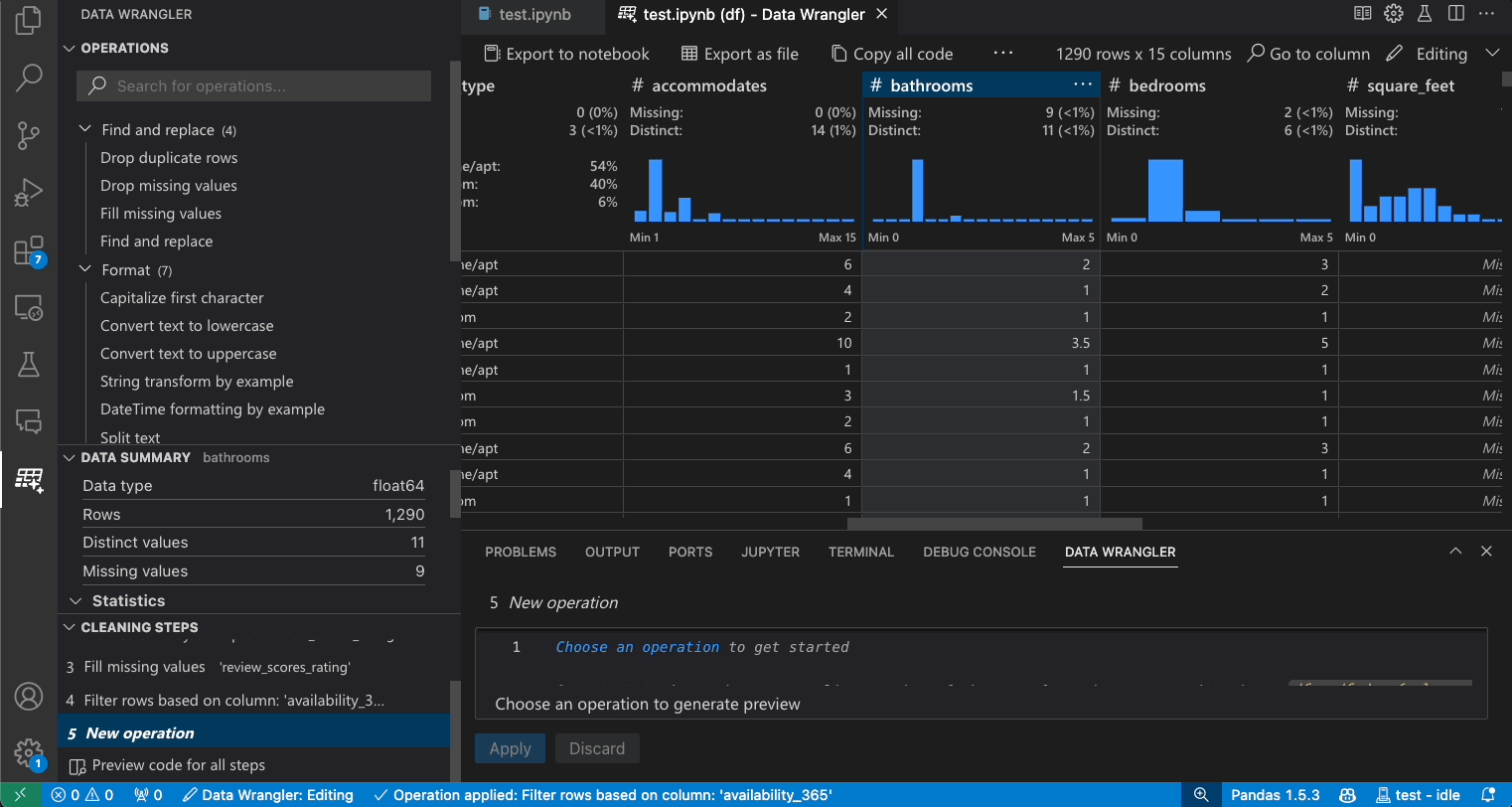
疑難排解
一般核心連線問題
如需一般連線問題,請參閱上方「連線到 Python 核心」章節,以了解其他連線方法。若要偵錯與本機 Python 直譯器選項相關的問題,一種可能解決問題的方法是安裝不同版本的 Jupyter 和 Python 擴充功能。例如,如果已安裝穩定版本的擴充功能,您可以安裝預先發行版本 (反之亦然)。
若要清除已快取的核心,您可以從命令面板執行 Data Wrangler: 清除快取的執行階段 命令 ⇧⌘P (Windows、Linux Ctrl+Shift+P)。
開啟資料檔案時出現 UnicodeDecodeError
如果您在直接從 Data Wrangler 開啟資料檔案時遇到 UnicodeDecodeError,則可能是由兩個可能的問題所造成
- 您嘗試開啟的檔案具有 UTF-8 以外的編碼
- 檔案已損毀。
若要解決此錯誤,您需要從 Jupyter Notebook 開啟 Data Wrangler,而不是直接從資料檔案開啟。使用 Jupyter Notebook 使用 Pandas 讀取檔案,例如使用 read_csv 方法。在 read 方法中,使用 encoding 和/或 encoding_errors 參數來定義要使用的編碼或如何處理編碼錯誤。如果您不知道哪種編碼可能適用於此檔案,您可以嘗試使用 chardet 等程式庫來嘗試推斷有效的編碼。
問題與意見反應
如果您有問題、功能要求或任何其他意見反應,請在我們的 GitHub 存放庫上提交 Issue:https://github.com/microsoft/vscode-data-wrangler/issues/new/choose
資料與遙測
適用於 Visual Studio Code 的 Microsoft Data Wrangler 擴充功能會收集使用資料並將其傳送給 Microsoft,以協助我們改進產品和服務。請閱讀我們的隱私權聲明以深入了解。此擴充功能遵循 telemetry.telemetryLevel 設定,您可以在 https://vscode.dev.org.tw/docs/configure/telemetry 深入了解。