VS Code Data Wrangler 快速入門指南
Data Wrangler 是一個以程式碼為中心的資料檢視和清理工具,已整合至 VS Code 和 VS Code Jupyter Notebooks 中。它提供豐富的使用者介面來檢視和分析您的資料、顯示具洞察力的欄統計資料和視覺化效果,並在您清理和轉換資料時自動產生 Pandas 程式碼。
以下範例說明從 Notebook 開啟 Data Wrangler,以使用內建操作分析和清理資料。然後,自動產生的程式碼會匯出回 Notebook。
本頁面的目標是協助您快速開始使用 Data Wrangler。
設定您的環境
- 如果您尚未安裝 Python,請立即安裝(注意: Data Wrangler 僅支援 Python 3.8 或更高版本)。
- 安裝 Data Wrangler 擴充功能
當您第一次啟動 Data Wrangler 時,它會詢問您要連線至哪個 Python 核心。它也會檢查您的機器和環境,以查看是否已安裝必要的 Python 套件,例如 Pandas。
開啟 Data Wrangler
任何時候您在 Data Wrangler 中,您都處於沙箱環境中,這表示您可以安全地探索和轉換資料。在您明確匯出變更之前,原始資料集不會被修改。
從 Jupyter Notebook 啟動 Data Wrangler
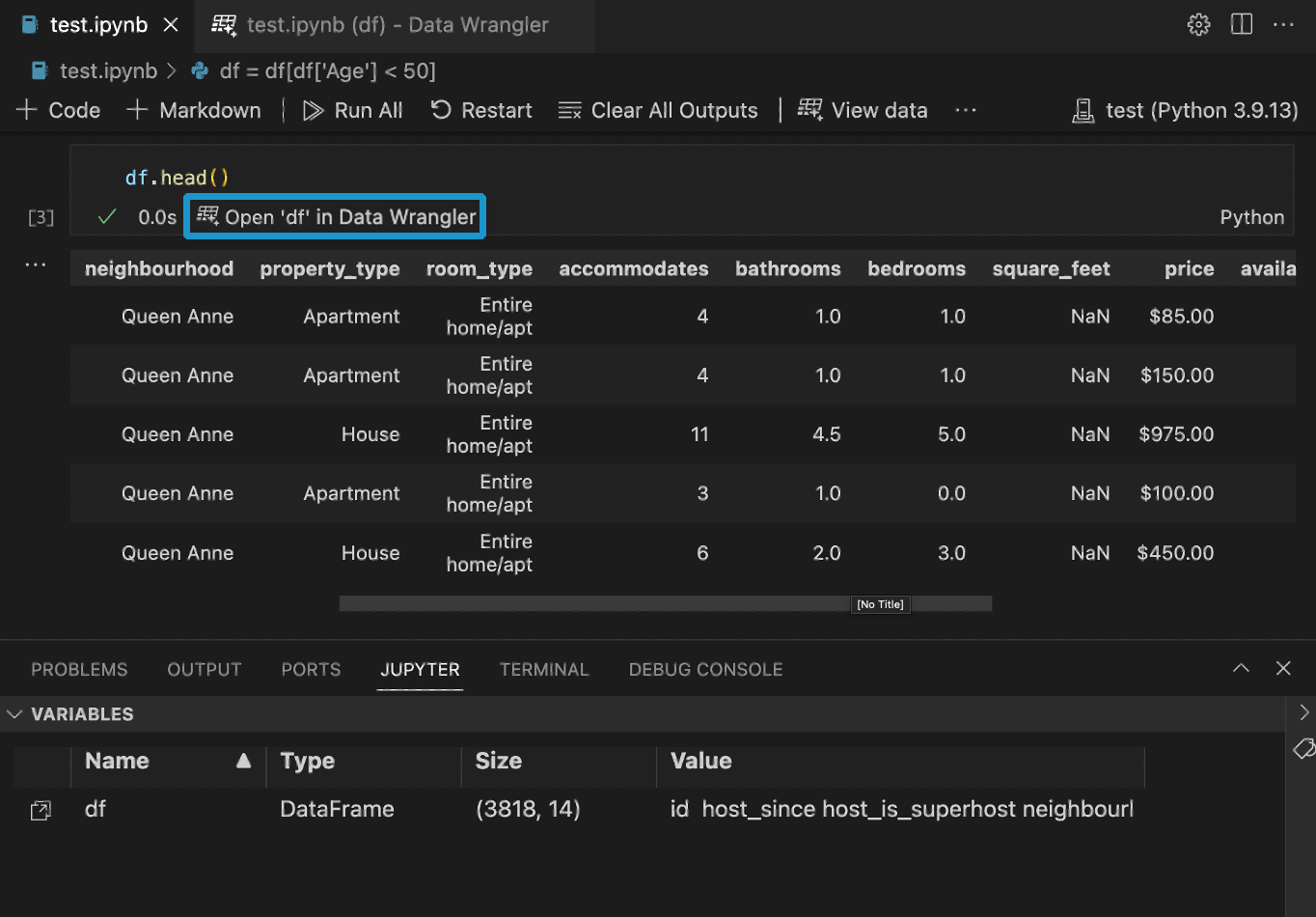
如果您在 Notebook 中有 Pandas 資料框架,現在您會在執行 df.head()、df.tail()、display(df)、print(df) 和 df 之後,在儲存格底部看到在 Data Wrangler 中開啟 'df' 按鈕(其中 df 是資料框架的變數名稱)。
直接從檔案啟動 Data Wrangler
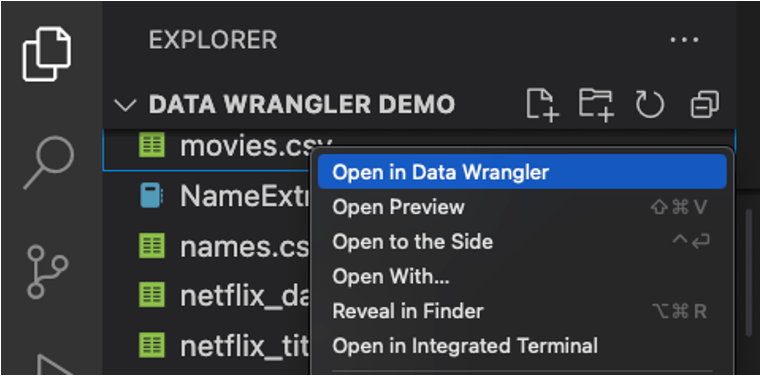
您也可以直接從本機檔案(例如 .csv)啟動 Data Wrangler。若要執行此操作,請在 VS Code 中開啟任何包含您要開啟之檔案的資料夾。在檔案總管檢視中,以滑鼠右鍵按一下檔案,然後按一下在 Data Wrangler 中開啟。
UI 導覽
Data Wrangler 在處理您的資料時有兩種模式。以下章節將說明每種模式的詳細資訊。
- 檢視模式: 檢視模式最佳化了介面,讓您可以快速檢視、篩選和排序資料。此模式非常適合對資料集進行初始探索。
- 編輯模式: 編輯模式最佳化了介面,讓您可以對資料集套用轉換、清理或修改。當您在介面中套用這些轉換時,Data Wrangler 會自動產生相關的 Pandas 程式碼,並且可以將其匯出回您的 Notebook 以重複使用。
注意:依預設,Data Wrangler 會在檢視模式中開啟。您可以在設定編輯器 中變更此行為。
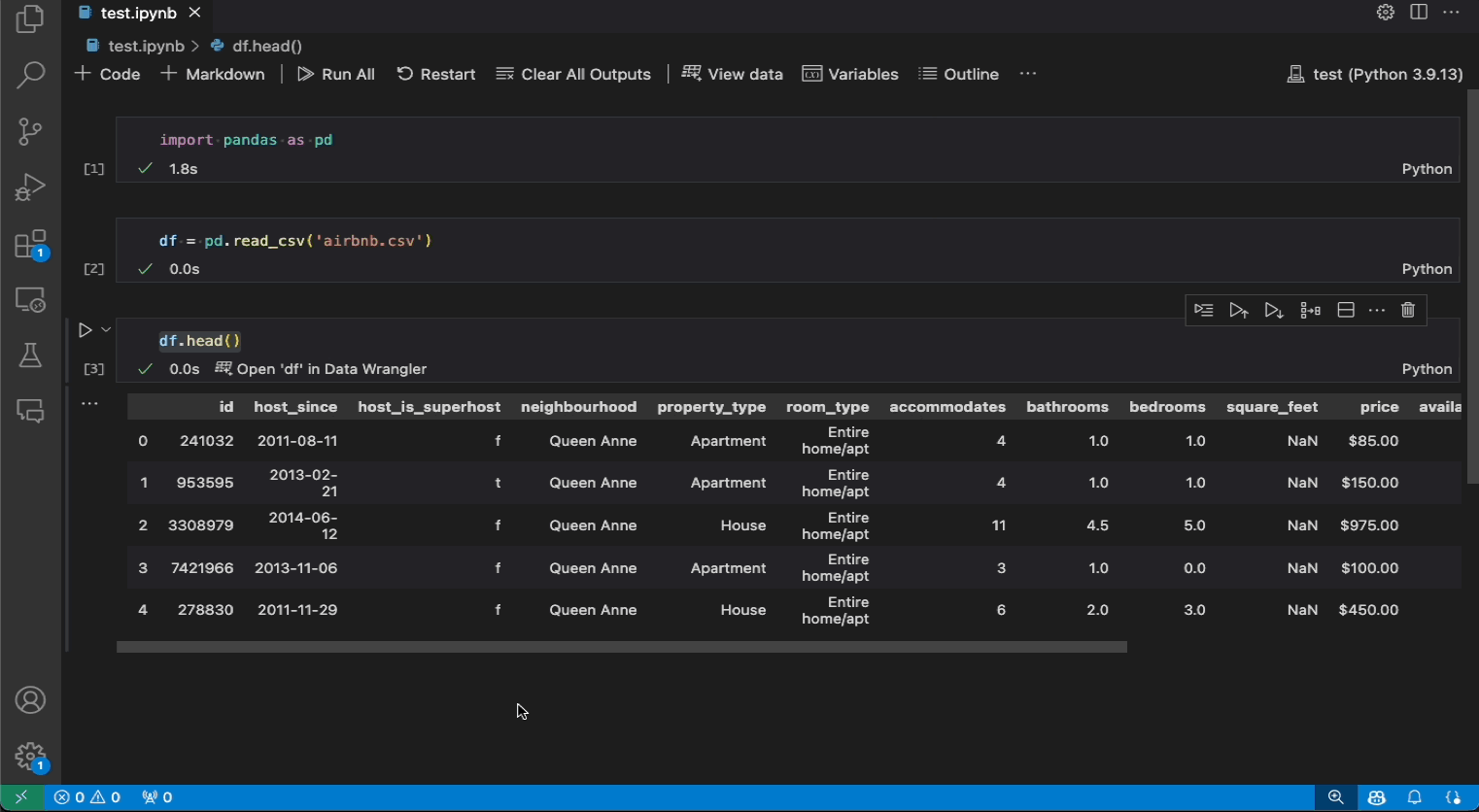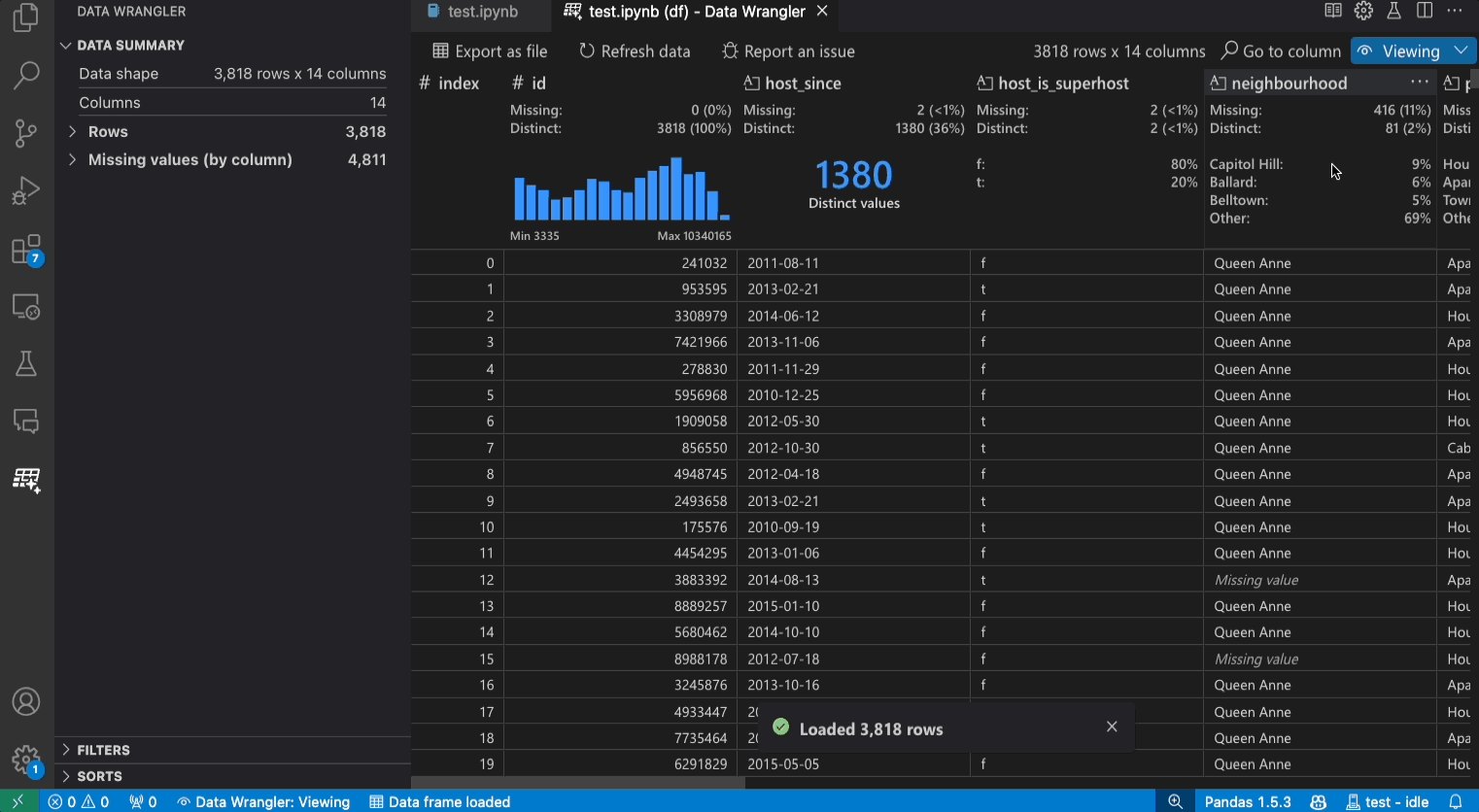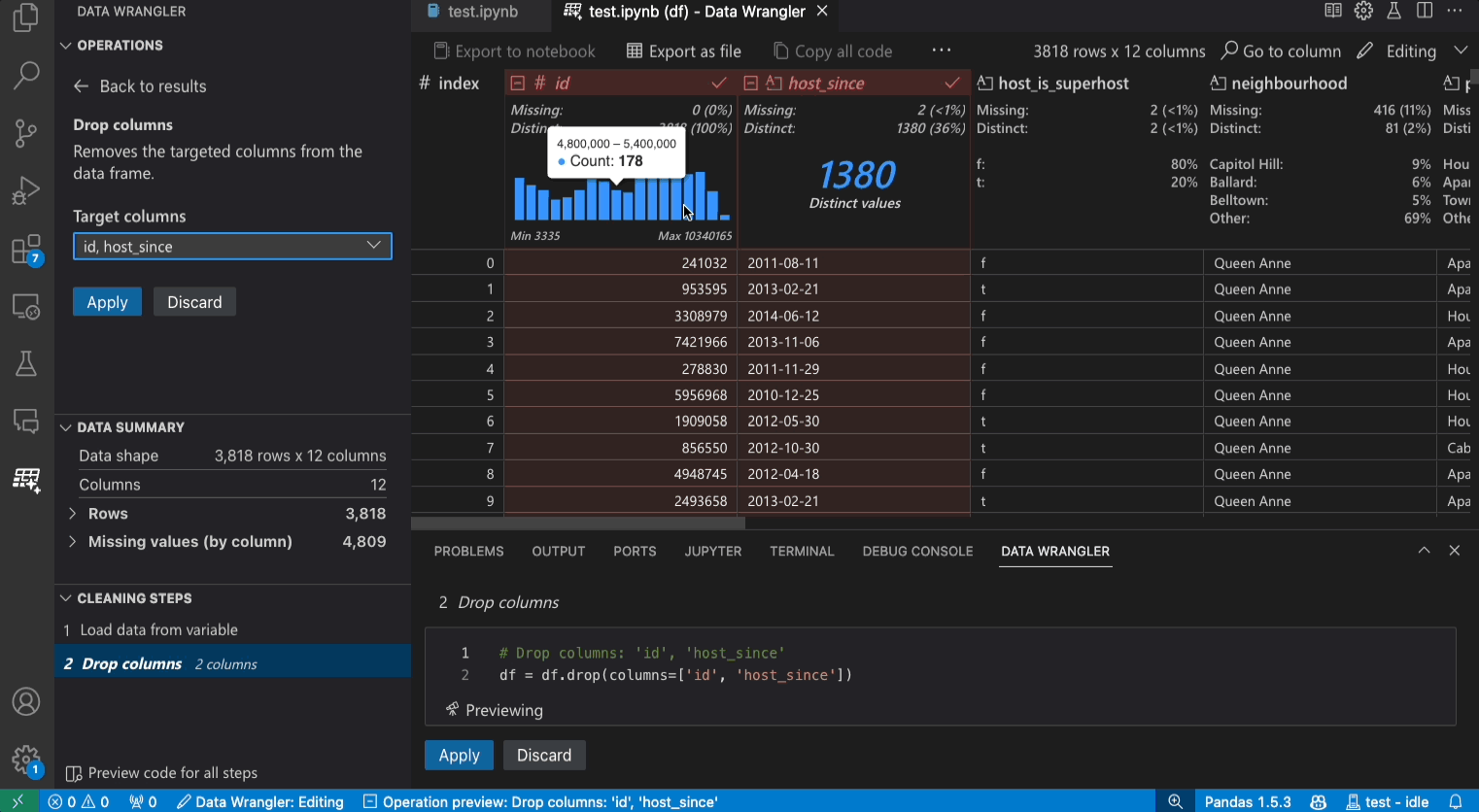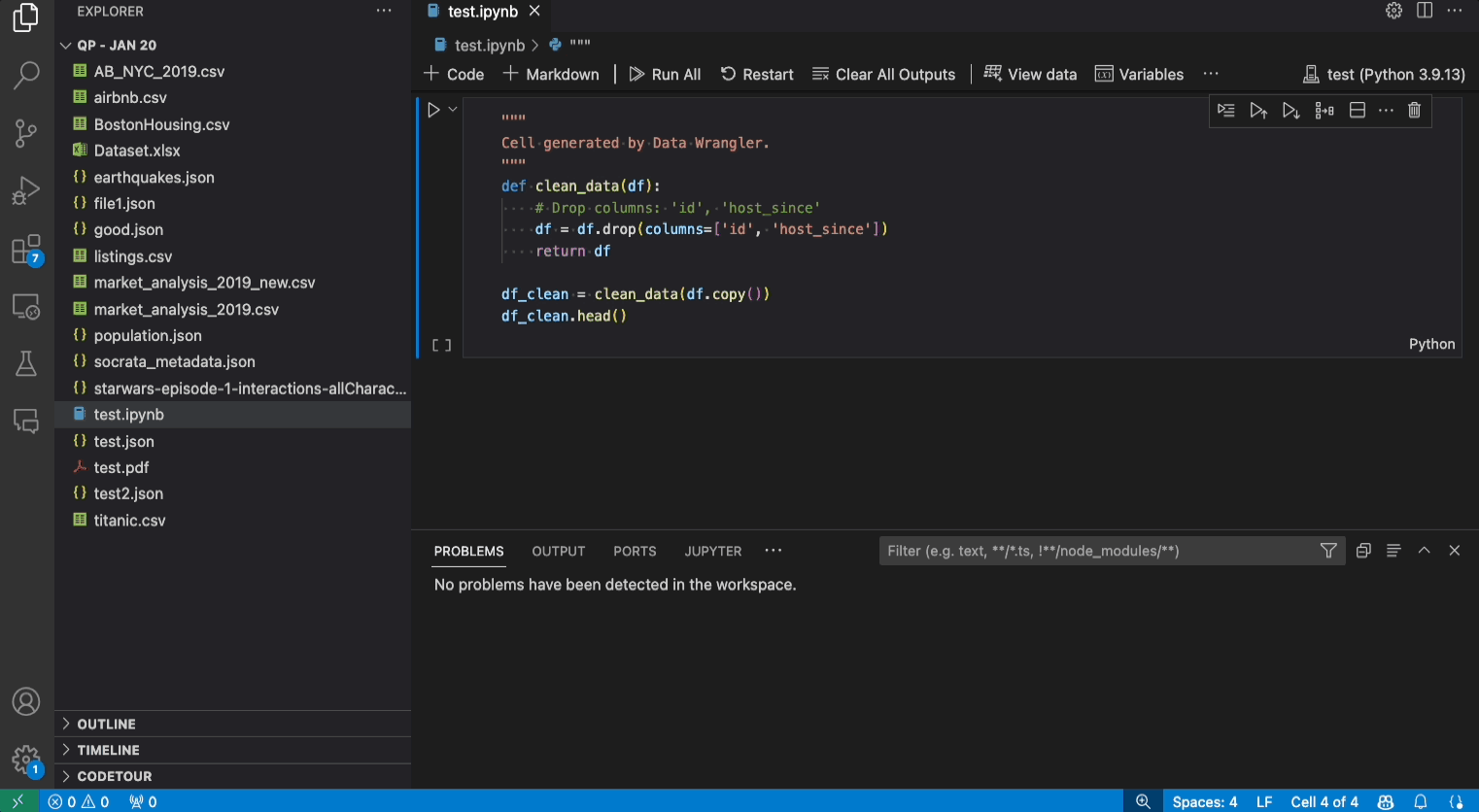
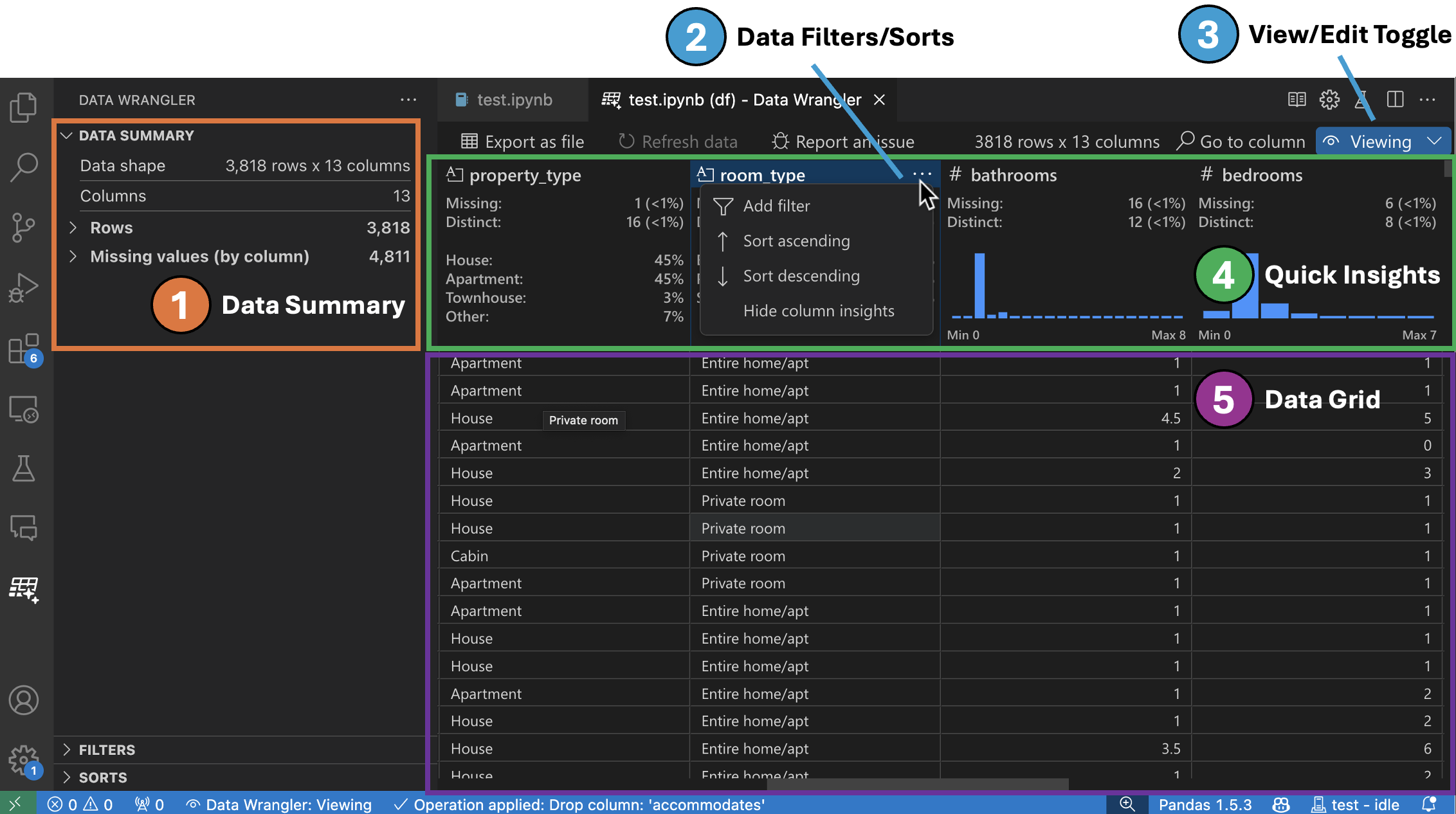
檢視模式介面
-
資料摘要面板會顯示整體資料集或特定欄(如果已選取)的詳細摘要統計資料。
-
您可以從欄的標頭選單中,對欄套用任何資料篩選/排序。
-
在 Data Wrangler 的檢視或編輯模式之間切換,以存取內建的資料操作。
-
快速深入解析標頭是您可以快速查看每個欄的寶貴資訊的地方。根據欄的資料類型,快速深入解析會顯示資料的分佈或資料點的頻率,以及遺失值和相異值。
-
資料網格為您提供可捲動的窗格,您可以在其中檢視整個資料集。
編輯模式介面
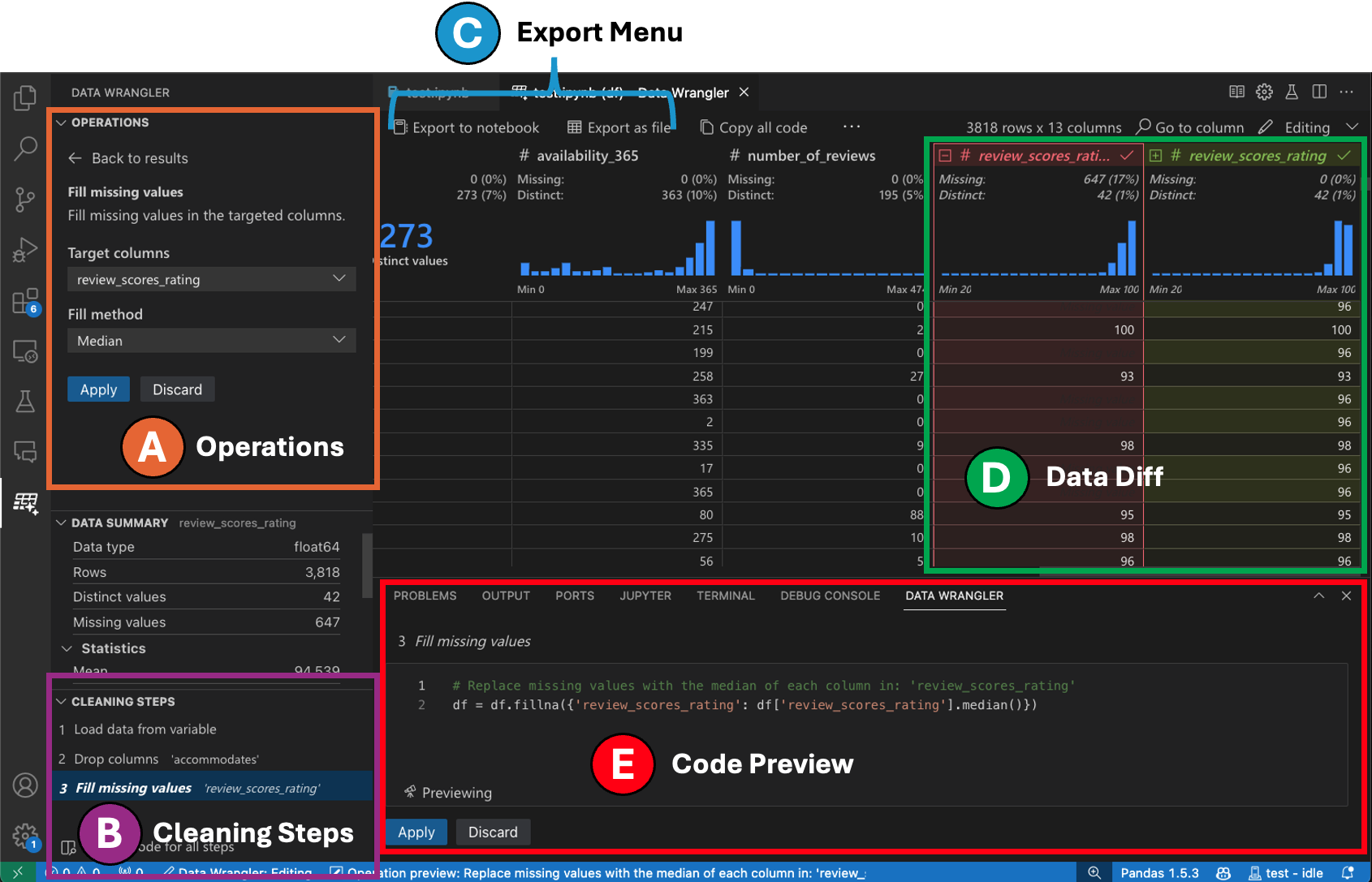
切換到編輯模式會在 Data Wrangler 中啟用其他功能和使用者介面元素。在以下螢幕擷取畫面中,我們使用 Data Wrangler 將最後一欄中的遺失值取代為該欄的中位數。
-
操作面板是您可以搜尋所有 Data Wrangler 內建資料操作的地方。這些操作依類別組織。
-
清理步驟面板會顯示先前已套用的所有操作的清單。它讓使用者可以還原特定操作或編輯最近的操作。選取步驟將會醒目提示資料網格中的變更,並顯示與該操作關聯的產生程式碼。
-
匯出選單可讓您將程式碼匯出回 Jupyter Notebook,或將資料匯出到新檔案。
-
當您選取操作並預覽其對資料的影響時,網格會覆疊資料差異檢視,顯示您對資料所做的變更。
-
程式碼預覽區段會顯示在選取操作時 Data Wrangler 產生的 Python 和 Pandas 程式碼。當未選取任何操作時,它會保持空白。您可以編輯產生的程式碼,這會導致資料網格醒目提示對資料的影響。
範例:取代資料集中遺失的值
給定資料集,常見的資料清理工作之一是處理資料中存在的任何遺失值。以下範例說明如何使用 Data Wrangler 將欄中的遺失值取代為該欄的中位數。雖然轉換是透過介面完成的,但 Data Wrangler 也會自動產生取代遺失值所需的 Python 和 Pandas 程式碼。
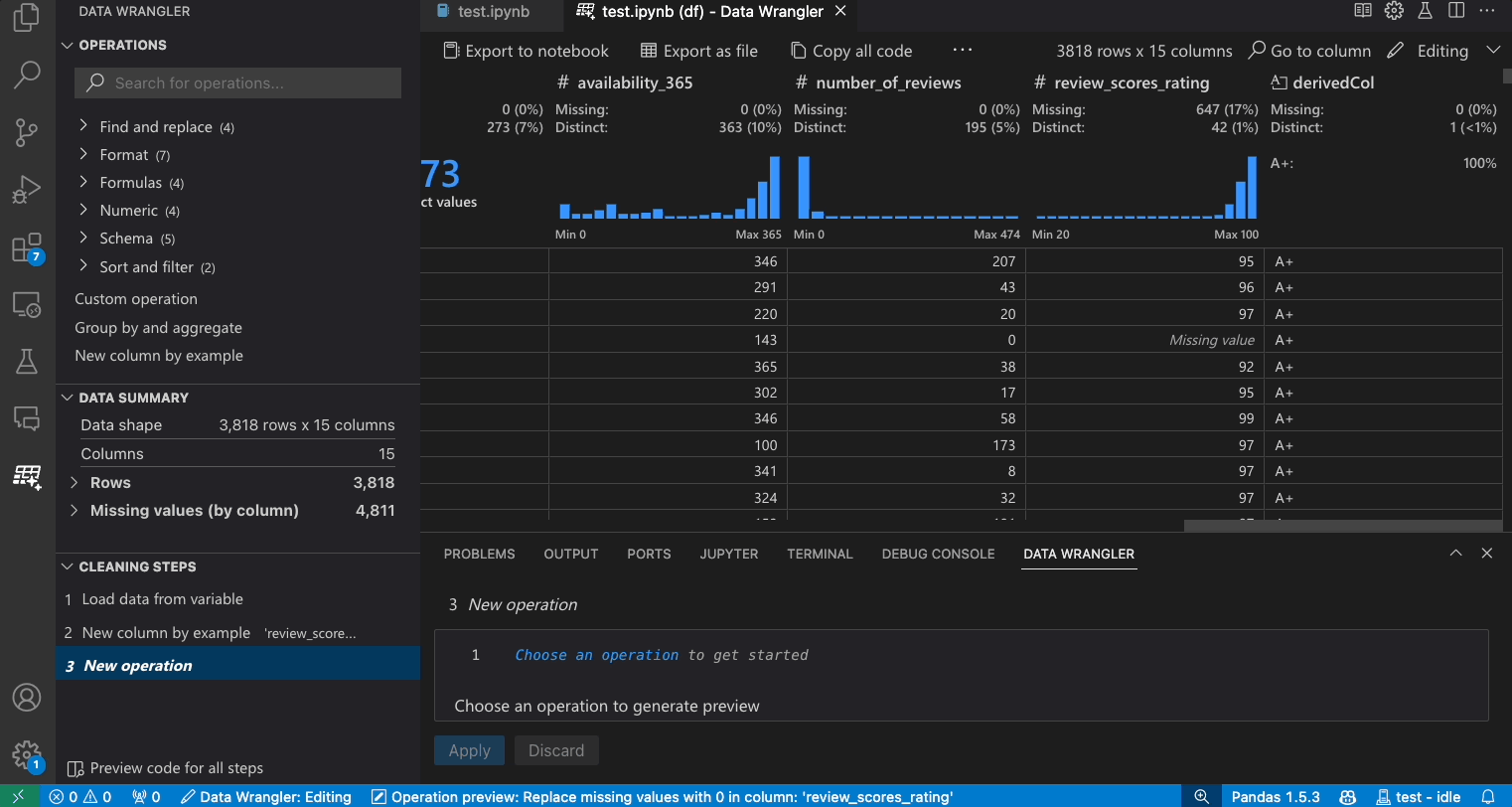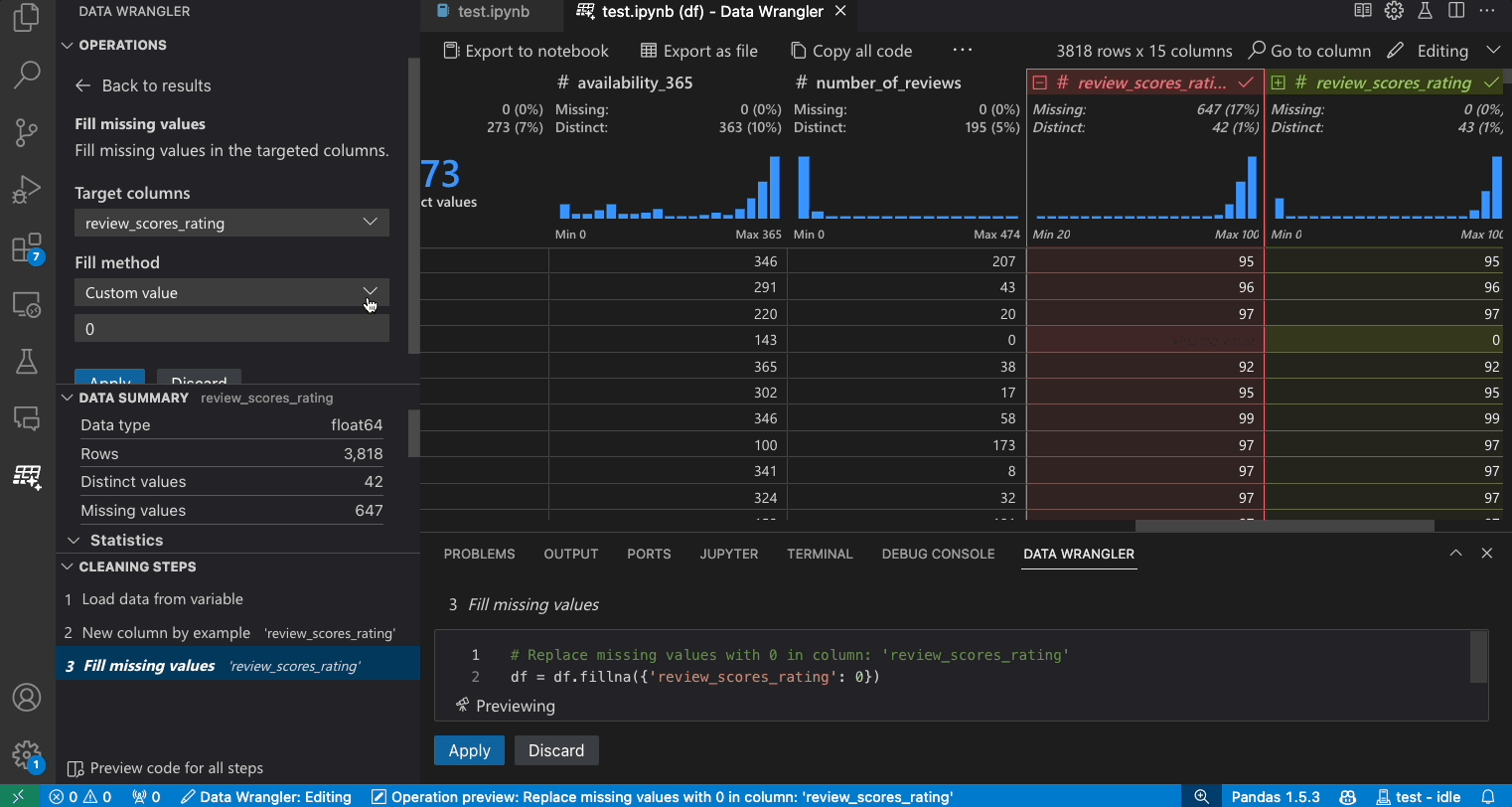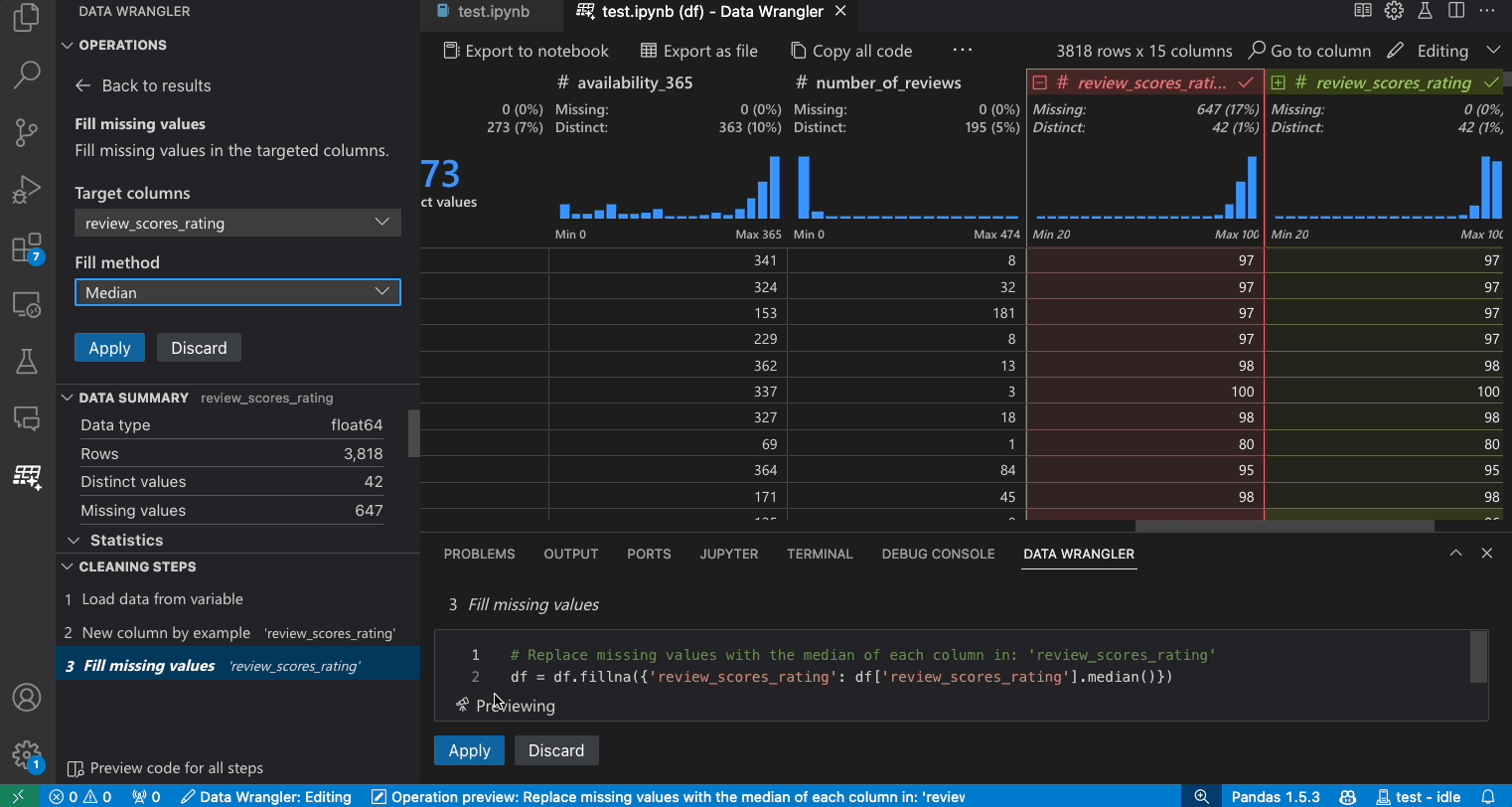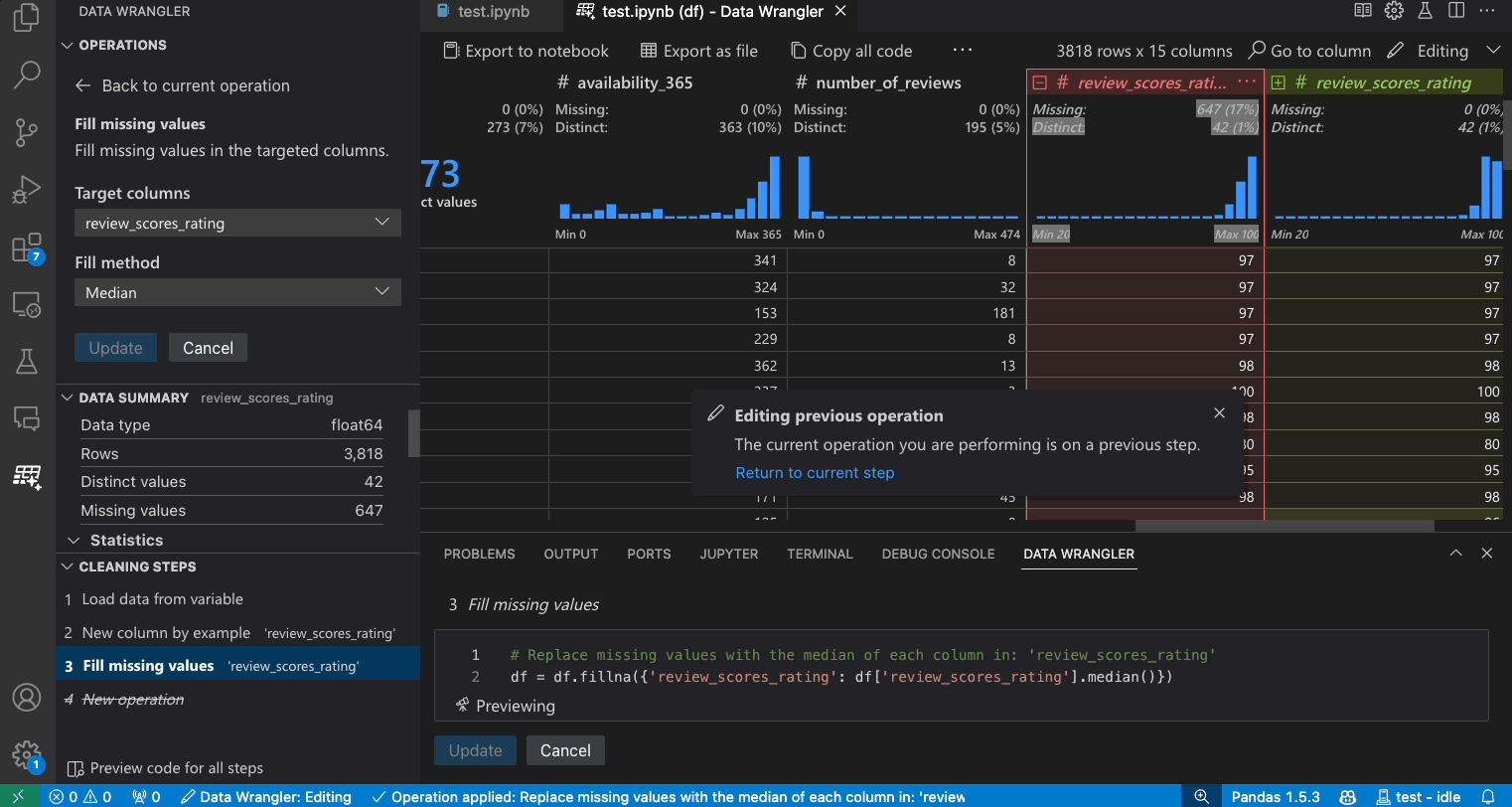
- 在操作面板中,搜尋填滿遺失值操作。
- 在參數中指定您要用什麼來取代遺失值。在此案例中,我們將使用欄的中位數來取代遺失值。
- 驗證資料網格是否在資料差異中顯示正確的變更。
- 驗證 Data Wrangler 產生的程式碼是否符合您的預期。
- 套用操作,它將新增至您的清理步驟歷程記錄。
後續步驟
本頁面涵蓋如何快速開始使用 Data Wrangler。如需 Data Wrangler 的完整文件和教學課程,包括 Data Wrangler 目前支援的所有內建操作,請參閱以下頁面。